10 Análise Discriminante
A Análise Discriminante (AD) é uma técnica estatística multivariada utilizada para descrever e classificar observações em grupos pré-definidos. A partir de um conjunto de variáveis preditoras, a AD busca encontrar combinações lineares dessas variáveis — chamadas de funções discriminantes — que maximizem a separação entre os grupos.
Em contraste com a Análise de Agrupamentos (Capítulo 9) — uma técnica de aprendizagem não supervisionada que visa descobrir grupos em um conjunto de dados —, a Análise Discriminante é uma técnica de aprendizagem supervisionada. Isso significa que partimos de uma classificação de grupos já conhecida e o objetivo é encontrar uma regra que melhor separe esses grupos, permitindo-nos, assim, classificar novas observações.
A AD possui duas finalidades principais:
- Separação (Análise exploratória): Encontrar as dimensões (funções discriminantes) que melhor revelam as diferenças entre as populações, e interpretar tais funções, a fim de entender quais características levam à distinção dos grupos.
- Classificação (Análise preditiva): Desenvolver uma regra para alocar novas observações, cujas afiliações de grupo são desconhecidas, a um dos grupos existentes.
10.1 Regras de discriminação para dois grupos
Para alocar os indivíduos em seus grupos mais prováveis, devemos definir uma regra de discriminação ou classificação. Esse é motivado probabilisticamente e tem como objetivo minimizar o custo de alocação/classificação incorreta, i.e., o erro em afirmar que um objeto pertence um grupo, quando na verdade pertence a outro.
Formalmente, considere um vetor p-dimensional de variáveis aleatórias \(\mathbf{X}\), e duas populações distintas \(\pi_1\) e \(\pi_2\) com funções densidade de probabilidade \(f_1(\mathbf{x})\) e \(f_2(\mathbf{x})\), respectivamente.
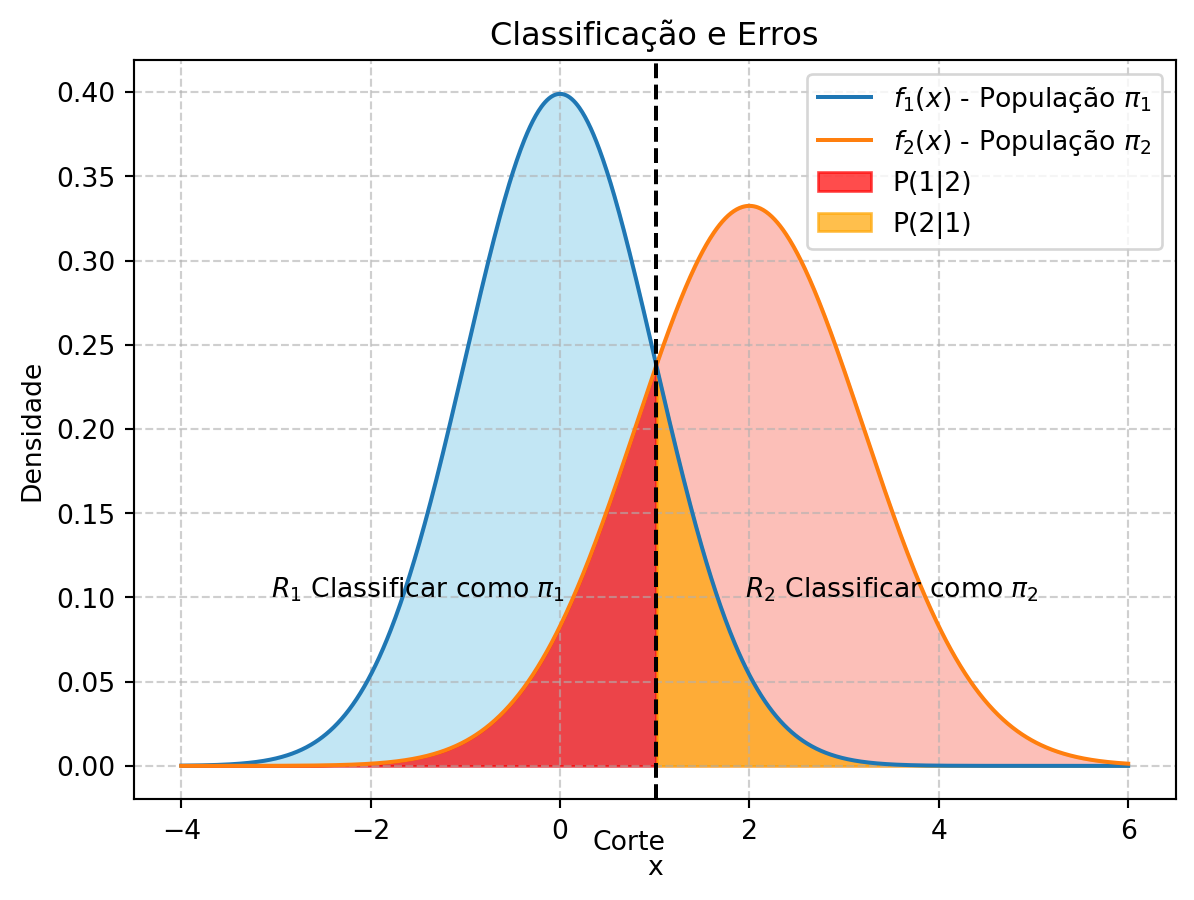
Seja \(\Omega\) o espaço amostral de \(\mathbf{X}\). A criação de uma regra de discriminação pode ser formulada como a tarefa de particionar \(\Omega = R_1 \cup R_2\), onde \(R_1\) e \(R_2\) são as partições do espaço nas quais os objetos ali pertencentes são alocados em \(\pi_1\) e \(\pi_2\), respectivamente.
Denotamos como \(p_1\) e \(p_2\) as probabilidades a priori de \(\pi_1\) e \(\pi_2\), respectivamente. Esses valores podem ser por exemplo, a proporção populacional de cada um dos grupos. As probabilidades de alocação correta e incorreta das observações são,
- Corretamente alocado em \(\pi_1\): \(P(X \in R_1 | \pi_1)P(\pi_1) = P(1|1)p_1\)
- Incorretamente alocado em \(\pi_1\): \(P(X \in R_1 | \pi_2)P(\pi_2) = P(1|2)p_2\)
- Corretamente alocado em \(\pi_2\): \(P(X \in R_2 | \pi_2)P(\pi_2) = P(2|2)p_2\)
- Incorretamente alocado em \(\pi_2\): \(P(X \in R_2 | \pi_1)P(\pi_1) = P(2|1)p_1\)
Note que existem dois tipos distintos de erros de alocação, probabilisticamente definidos por \(P(1|2)\) e \(P(2|1)\), ilustrados esquematicamente na Figura 10.1.
No caso mais simples, pode-se assumir que os erros são igualmente importantes. No entanto, em diversos casos tal suposição não é razoável. Por exemplo, na análise de crédito, o custo de classificar um mau pagador como um bom pagador (concedendo um empréstimo que não será quitado) é drasticamente maior do que o custo de classificar um bom pagador como um mau pagador (negando um empréstimo e perdendo o lucro do juros). Nesses casos, definimos os custos, \(C(1|2)\): Custo de alocação incorreta em \(\pi_1\) e \(C(2|1)\): Custo de alocação incorreta em \(\pi_2\). Os custos de alocação incorretas podem ser representados em uma matriz de custos:
| População Verdadeira | Classifica como \(\pi_1\) | Classifica como \(\pi_2\) |
|---|---|---|
| \(\pi_1\) | 0 | \(C(2|1)\) |
| \(\pi_2\) | \(C(1|2)\) | 0 |
Definição 10.1 O custo médio de classificação incorreta (ECM) é o custo esperado dos erros de classificação, ponderado pelas probabilidades a priori de cada grupo. É definido como:
\[ ECM = C(1|2)P(1|2)p_2 + C(2|1)P(2|1)p_1 \]
O objetivo de uma regra de classificação ótima é, portanto, minimizar o Custo Médio de Classificação Incorreta (ECM). As regiões de classificação \(R_1\) e \(R_2\) que atingem esse mínimo são definidas pela seguinte regra de desigualdade:
\(R_1\): Alocar em \(\pi_1\) se \[ \frac{f_1(\mathbf{x})}{f_2(\mathbf{x})} \ge \frac{C(1|2)}{C(2|1)} \frac{p_2}{p_1} \]
\(R_2\): Alocar em \(\pi_2\) se \[ \frac{f_1(\mathbf{x})}{f_2(\mathbf{x})} < \frac{C(1|2)}{C(2|1)} \frac{p_2}{p_1} \]
A regra de alocação ótima, portanto, equilibra três componentes essenciais:
- A razão de verossimilhança, \(\frac{f_1(\mathbf{x})}{f_2(\mathbf{x})}\), que compara quão provável é a observação \(\mathbf{x}\) em cada população.
- A razão de custos, \(\frac{C(1|2)}{C(2|1)}\), que pondera a gravidade de cada tipo de erro.
- A razão das probabilidades a priori, \(\frac{p_2}{p_1}\), que considera a frequência relativa de cada população.
Quando os custos de classificação incorreta são considerados iguais (\(C(1|2) = C(2|1) = C\)), o ECM se torna proporcional à probabilidade total de classificação incorreta. Se os custos forem desconhecidos, uma prática comum é assumi-los como iguais, o que nos leva a minimizar a seguinte métrica.
Definição 10.2 A probabilidade total de classificação incorreta (TPM) é a probabilidade de classificar erroneamente uma observação, ponderada pelas probabilidades a priori de cada grupo. É definida como:
\[ \begin{split} TPM &= p_1 P(2|1) + p_2 P(1|2) \\ &= p_1 \int_{R_2} f_1(\mathbf{x})d\mathbf{x} + p_2 \int_{R_1} f_2(\mathbf{x})d\mathbf{x} \end{split} \]
A regra que minimiza o TPM é a mesma que minimiza o ECM, apenas com \(C(1|2)/C(2|1) = 1\).
Nota
Os acrônimos ECM e TPM vêm do inglês Expected Cost of Misclassification e Total Probability of Misclassification, respectivamente.
10.2 Análise Discriminante Linear (LDA) para Dois Grupos
A Análise Discriminante Linear é o método de discriminação mais fundamental. Seu objetivo é encontrar a combinação linear das variáveis preditoras que melhor separa os dois grupos. Essa ideia pode ser abordada de duas perspectivas principais: a de Fisher, que busca maximizar a separação, e a probabilística, que busca minimizar o erro de classificação sob certas condições. Ambas chegam à mesma solução.
10.2.1 A Perspectiva de Fisher: Maximizando a Separação
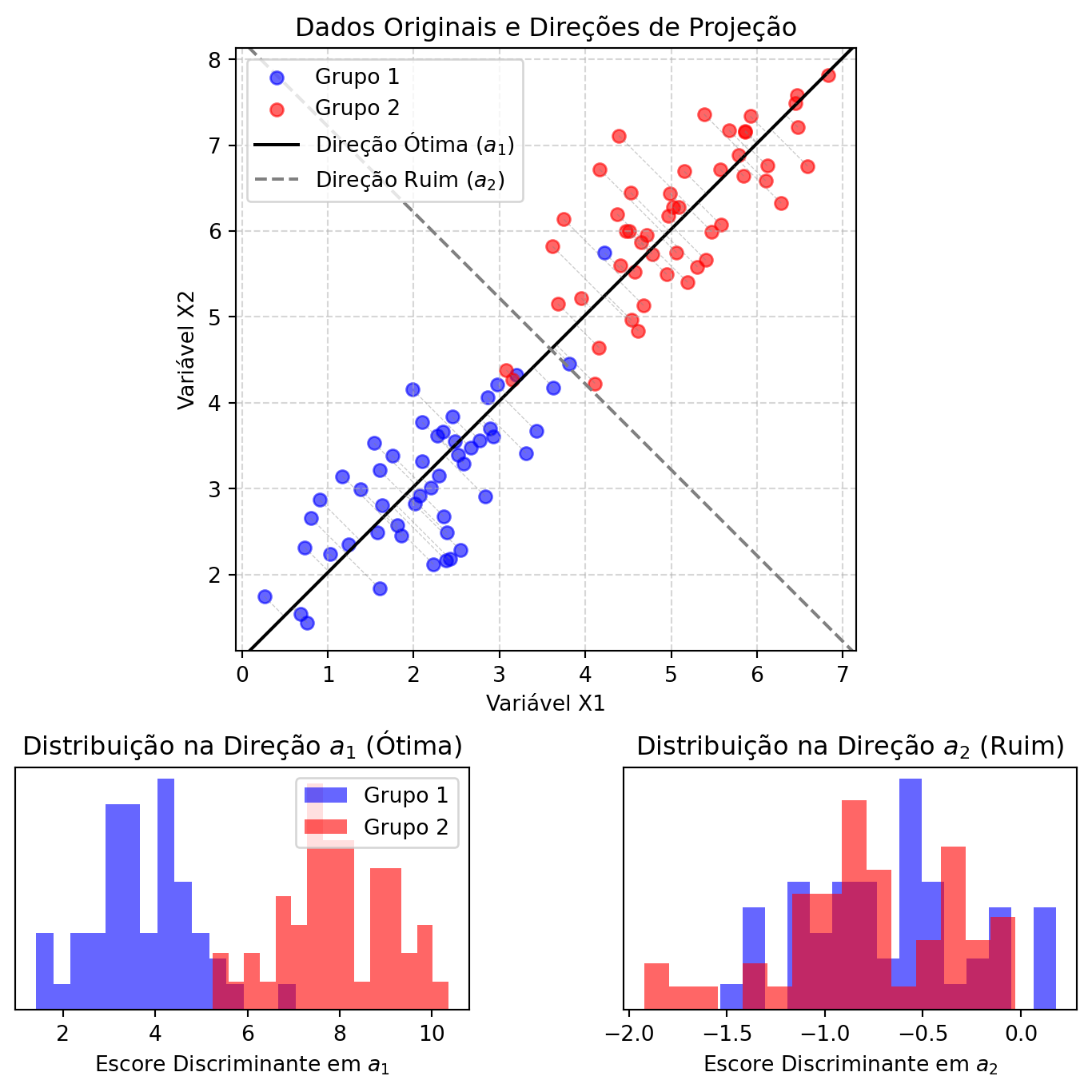
A intuição original de R.A. Fisher era geométrica e notavelmente simples: se quisermos separar dois grupos, devemos encontrar a projeção dos dados que torne essa separação o mais clara possível.
Imagine que você está olhando para duas nuvens de pontos no espaço. Se você as olhar de um ângulo ruim, elas podem parecer sobrepostas e indistinguíveis. Se você encontrar o ângulo certo, no entanto, as duas nuvens se separam claramente. Esse “ângulo de visão” em estatística é uma combinação linear das variáveis originais, que projeta os dados de um espaço p-dimensional para uma única linha.
O critério de Fisher, portanto, busca a projeção (a combinação linear y = a'x) que simultaneamente:
- Maximiza a distância entre as médias dos grupos projetados.
- Minimiza a variância dentro de cada grupo projetado.
Em outras palavras, queremos que os grupos fiquem o mais “espalhados” possível entre si, e o mais “compactos” possível internamente. O vetor de coeficientes a que realiza essa tarefa define a função discriminante linear. O método recebe esse nome porque o escore resultante é uma função linear das variáveis originais.
A Figura 10.2 ilustra a intuição de Fisher em duas dimensões. No espaço original das variáveis \(X_1\) e \(X_2\), os dois grupos possuem alguma sobreposição. Se projetarmos os dados em uma direção inadequada (como a linha \(a_2\)), os grupos projetados se misturam consideravelmente, tornando a classificação difícil. No entanto, ao projetar os dados na direção ótima encontrada pela LDA (a linha \(a_1\)), as distribuições dos escores resultantes ficam muito mais separadas, permitindo uma discriminação eficaz.
Formalmente, o critério de Fisher busca o vetor \(\mathbf{a}\) que maximiza a razão entre a variância entre grupos e a variância dentro dos grupos:
\[ J(\mathbf{a}) = \frac{(\mathbf{a}'(\boldsymbol{\mu}_1 - \boldsymbol{\mu}_2))^2}{\mathbf{a}'\mathbf{\Sigma}_W\mathbf{a}} \]
onde \(\mathbf{\Sigma}_W\) é a matriz de covariância intra-grupos (ponderada). O numerador mede a separação entre as médias projetadas, enquanto o denominador mede a dispersão total dentro dos grupos.
NotaDerivação do Critério de Fisher
Para maximizar \(J(\mathbf{a})\), derivamos em relação a \(\mathbf{a}\) e igualamos a zero. Usando cálculo matricial, obtemos:
\[ \frac{\partial J}{\partial \mathbf{a}} = 0 \quad \Rightarrow \quad \mathbf{\Sigma}_W \mathbf{a} \propto (\boldsymbol{\mu}_1 - \boldsymbol{\mu}_2) \]
Portanto, a solução é \(\mathbf{a} \propto \mathbf{\Sigma}_W^{-1}(\boldsymbol{\mu}_1 - \boldsymbol{\mu}_2)\). Na prática, estimamos com a matriz pooled:
\[ \hat{\mathbf{a}} = \mathbf{S}_{pooled}^{-1}(\bar{\mathbf{x}}_1 - \bar{\mathbf{x}}_2) \]
Em vez de detalhar completamente essa derivação aqui, vamos explorar a perspectiva probabilística, que, sob certas condições, chega a um resultado idêntico, fornecendo uma base estatística mais robusta para a regra de classificação.
10.2.2 A Perspectiva Probabilística: Minimizando o Erro
Uma abordagem alternativa parte da regra de classificação ótima que minimiza o erro total (Definição 10.1). Assumindo custos iguais, alocamos uma observação \(\mathbf{x}\) ao grupo \(\pi_1\) se for mais provável que ela venha de \(\pi_1\) do que de \(\pi_2\) (ponderado pelas probabilidades a priori), ou seja, se \(p_1 f_1(\mathbf{x}) \ge p_2 f_2(\mathbf{x})\).
Para tornar essa regra explícita, a LDA introduz dois pressupostos-chave:
- Normalidade: Os dados de cada grupo seguem uma distribuição Normal Multivariada, \(\mathbf{X}_i \sim N_p(\boldsymbol{\mu}_i, \mathbf{\Sigma}_i)\).
- Homogeneidade de Covariâncias: As matrizes de covariância dos grupos são iguais, \(\mathbf{\Sigma}_1 = \mathbf{\Sigma}_2 = \mathbf{\Sigma}\).
A regra \(p_1 f_1(\mathbf{x}) \ge p_2 f_2(\mathbf{x})\) é equivalente a \(\ln(p_1 f_1(\mathbf{x})) \ge \ln(p_2 f_2(\mathbf{x}))\). Expandindo o logaritmo da densidade Normal Multivariada (e ignorando a constante \(-(p/2)\ln(2\pi)\)), temos:
\[ \ln(p_i) - \frac{1}{2} \ln|\mathbf{\Sigma}| - \frac{1}{2}(\mathbf{x} - \boldsymbol{\mu}_i)' \mathbf{\Sigma}^{-1} (\mathbf{x} - \boldsymbol{\mu}_i) \]
A desigualdade se torna:
\[ \ln(p_1) - \frac{1}{2} \ln|\mathbf{\Sigma}| - \frac{1}{2}(\mathbf{x} - \boldsymbol{\mu}_1)' \mathbf{\Sigma}^{-1} (\mathbf{x} - \boldsymbol{\mu}_1) \ge \ln(p_2) - \frac{1}{2} \ln|\mathbf{\Sigma}| - \frac{1}{2}(\mathbf{x} - \boldsymbol{\mu}_2)' \mathbf{\Sigma}^{-1} (\mathbf{x} - \boldsymbol{\mu}_2) \]
Os termos \(\ln|\mathbf{\Sigma}|\) se cancelam. Expandindo os termos quadráticos e simplificando, a regra de alocação para \(\pi_1\) se torna uma função linear da observação \(\mathbf{x}\).
NotaDetalhes da Simplificação
Cada termo quadrático pode ser expandido como:
\[ (\mathbf{x} - \boldsymbol{\mu}_i)' \mathbf{\Sigma}^{-1} (\mathbf{x} - \boldsymbol{\mu}_i) = \mathbf{x}'\mathbf{\Sigma}^{-1}\mathbf{x} - 2\boldsymbol{\mu}_i'\mathbf{\Sigma}^{-1}\mathbf{x} + \boldsymbol{\mu}_i'\mathbf{\Sigma}^{-1}\boldsymbol{\mu}_i \]
Quando subtraímos \(-\frac{1}{2}(\mathbf{x} - \boldsymbol{\mu}_1)'...\) de \(-\frac{1}{2}(\mathbf{x} - \boldsymbol{\mu}_2)'...\), os termos \(\mathbf{x}'\mathbf{\Sigma}^{-1}\mathbf{x}\) se cancelam (pois aparecem igualmente em ambos os lados), deixando apenas termos lineares em \(\mathbf{x}\) e constantes.
A expressão completa, conhecida como função discriminante linear populacional, é:
\[ \underbrace{(\boldsymbol{\mu}_1 - \boldsymbol{\mu}_2)'\mathbf{\Sigma}^{-1}\mathbf{x}}_{\text{Escore Discriminante Linear } (y)} \ge \underbrace{\frac{1}{2}(\boldsymbol{\mu}_1 - \boldsymbol{\mu}_2)'\mathbf{\Sigma}^{-1}(\boldsymbol{\mu}_1 + \boldsymbol{\mu}_2) + \ln\left(\frac{p_2}{p_1}\right)}_{\text{Ponto de Corte } (c)} \tag{10.1}\]
Esta regra pode ser escrita de forma compacta como \(y \ge c\). O escore discriminante linear (\(y\)) é obtido por \(y = \mathbf{a}'\mathbf{x}\), onde o vetor de coeficientes \(\mathbf{a} = \mathbf{\Sigma}^{-1}(\boldsymbol{\mu}_1 - \boldsymbol{\mu}_2)\) é idêntico ao encontrado pela abordagem de Fisher.
O ponto de corte \(c\) também pode ser expresso de forma mais intuitiva como a média dos escores médios de cada população, com um ajuste para as probabilidades a priori:
\[ c = \frac{1}{2}(\bar{y}_1 + \bar{y}_2) + \ln\left(\frac{p_2}{p_1}\right) \]
onde \(\bar{y}_1 = E[Y|\pi_1] = \mathbf{a}'\boldsymbol{\mu}_1\) e \(\bar{y}_2 = E[Y|\pi_2] = \mathbf{a}'\boldsymbol{\mu}_2\) são os escores discriminantes médios (esperados) para as populações \(\pi_1\) e \(\pi_2\), respectivamente.
A abordagem probabilística, portanto, não apenas confirma o vetor de projeção de Fisher, mas também fornece um ponto de corte ótimo com base estatística. Se as probabilidades a priori forem iguais, o ponto de corte se torna \(c = (\bar{y}_1 + \bar{y}_2) / 2\), o ponto médio exato entre as médias dos grupos projetados.
10.2.3 A Função Discriminante Amostral
Na prática, os parâmetros populacionais (\(\boldsymbol{\mu}_1, \boldsymbol{\mu}_2, \mathbf{\Sigma}\)) e as probabilidades a priori (\(p_1, p_2\)) são desconhecidos. Nós os substituímos por suas estimativas da amostra:
- \(\boldsymbol{\mu}_i\) é estimado pela média amostral do grupo \(i\), \(\bar{\mathbf{x}}_i\).
- \(p_i\) é estimado pela proporção amostral do grupo \(i\), \(n_i/n_{total}\).
- A covariância comum \(\mathbf{\Sigma}\) é estimada pela matriz de covariância combinada (pooled):
\[ \mathbf{S}_{pooled} = \frac{(n_1 - 1)\mathbf{S}_1 + (n_2 - 1)\mathbf{S}_2}{n_1 + n_2 - 2} \]
Substituindo esses valores, obtemos o vetor de coeficientes da função discriminante linear amostral:
\[ \hat{\mathbf{a}} = \mathbf{S}_{pooled}^{-1}(\bar{\mathbf{x}}_1 - \bar{\mathbf{x}}_2) \]
O escore discriminante amostral para uma observação \(\mathbf{x}\) é então \(\hat{y} = \hat{\mathbf{a}}'\mathbf{x}\). A regra de classificação é alocar uma nova observação \(\mathbf{x}_{new}\) a \(\pi_1\) se seu escore \(\hat{y}_{new}\) for maior que o ponto de corte ajustado \(\hat{c}\). O ponto de corte pode ser expresso de forma mais intuitiva usando as médias dos escores discriminantes para cada grupo:
- Média do escore para o grupo 1: \(\hat{\bar{y}}_1 = \hat{\mathbf{a}}'\bar{\mathbf{x}}_1\)
- Média do escore para o grupo 2: \(\hat{\bar{y}}_2 = \hat{\mathbf{a}}'\bar{\mathbf{x}}_2\)
O ponto de corte \(\hat{c}\) é então a média dos escores médios, ajustado pelas probabilidades a priori:
\[ \hat{c} = \frac{1}{2}(\hat{\bar{y}}_1 + \hat{\bar{y}}_2) + \ln\left(\frac{p_2}{p_1}\right) \]
Se as probabilidades a priori forem assumidas como iguais (\(p_1=p_2=0.5\)), o termo de log se anula, e o ponto de corte se torna simplesmente a média dos escores médios de cada grupo: \(\hat{c} = (\hat{\bar{y}}_1 + \hat{\bar{y}}_2)/2\). Isso reforça a intuição de que a fronteira de decisão fica exatamente no meio do caminho entre os centroides dos grupos projetados.
10.3 Análise discriminante quadrática para dois grupos
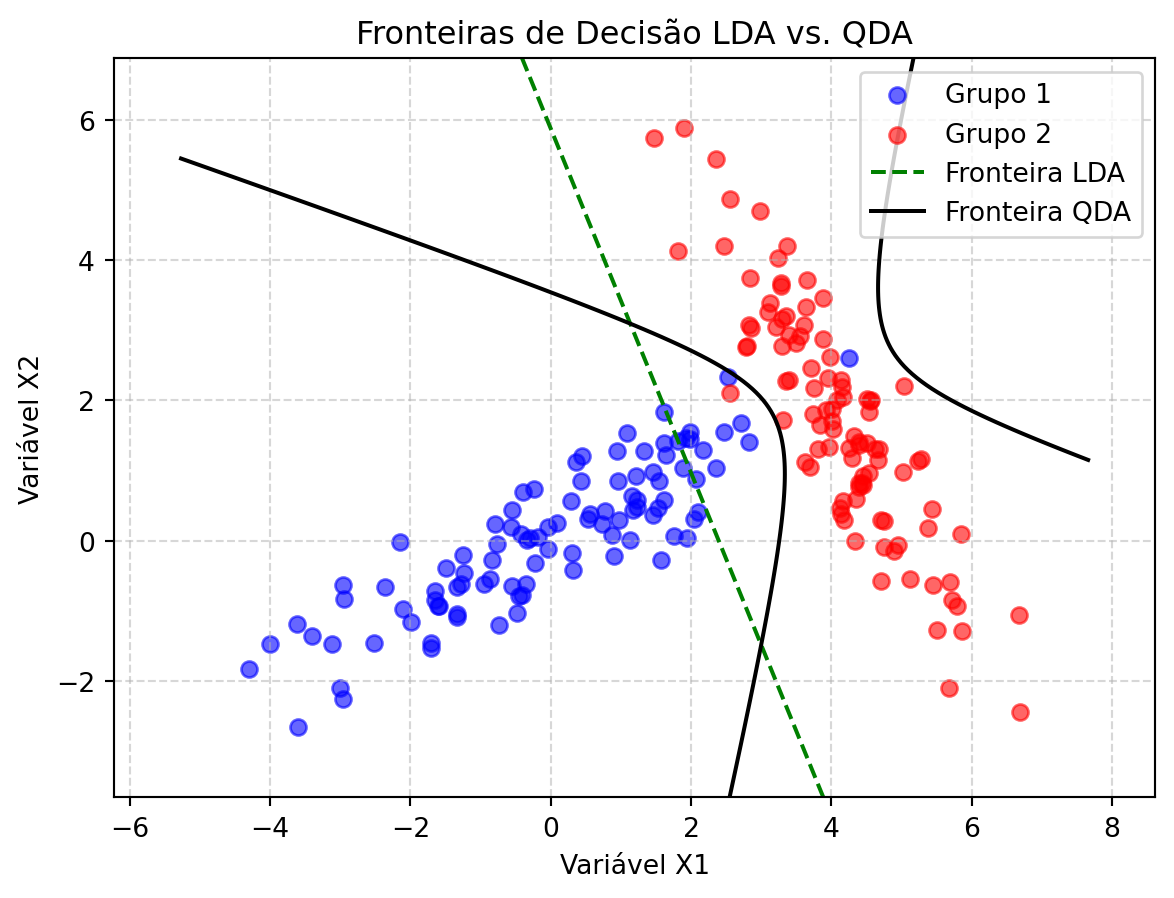
Quando o pressuposto de homogeneidade das matrizes de covariância é violado (\(\mathbf{\Sigma}_1 \neq \mathbf{\Sigma}_2\)), a LDA pode não ser a melhor abordagem. A Análise Discriminante Quadrática (QDA) surge como uma alternativa que não assume que as matrizes de covariância populacionais são iguais.
Partindo da regra geral de alocar \(\mathbf{x}\) em \(\pi_k\) que maximize \(\ln(p_k f_k(\mathbf{x}))\), e usando a densidade normal multivariada sem assumir \(\mathbf{\Sigma}_1 = \mathbf{\Sigma}_2\), o termo quadrático \((\mathbf{x} - \boldsymbol{\mu}_k)' \mathbf{\Sigma}_k^{-1} (\mathbf{x} - \boldsymbol{\mu}_k)\) não se cancela. A regra é então baseada no escore de discriminação quadrática para cada grupo:
\[ d_k^Q(\mathbf{x}) = -\frac{1}{2} \ln|\mathbf{\Sigma}_k| - \frac{1}{2}(\mathbf{x} - \boldsymbol{\mu}_k)' \mathbf{\Sigma}_k^{-1} (\mathbf{x} - \boldsymbol{\mu}_k) + \ln(p_k) \]
A observação \(\mathbf{x}\) é alocada à população \(\pi_k\) para a qual o escore \(d_k^Q(\mathbf{x})\) é maior. A fronteira de decisão, onde \(d_1^Q(\mathbf{x}) = d_2^Q(\mathbf{x})\), é uma função quadrática de \(\mathbf{x}\) (uma cônica), o que dá o nome ao método.
Na prática, com parâmetros desconhecidos, usamos as estimativas amostrais:
\[ \hat{d}_k^Q(\mathbf{x}) = -\frac{1}{2} \ln|\mathbf{S}_k| - \frac{1}{2}(\mathbf{x} - \bar{\mathbf{x}}_k)' \mathbf{S}_k^{-1} (\mathbf{x} - \bar{\mathbf{x}}_k) + \ln(p_k) \]
A diferença fundamental entre as fronteiras de decisão da LDA e da QDA é melhor compreendida visualmente. A Figura 10.3 mostra um cenário onde os dois grupos têm matrizes de covariância distintas. A LDA, restrita a uma fronteira linear, não consegue separar os grupos de forma eficaz. A QDA, por outro lado, cria uma fronteira quadrática que se adapta muito melhor à forma e orientação de cada grupo, resultando em uma classificação superior.
10.4 Avaliando a Qualidade da Separação
Para que a análise discriminante seja útil, deve haver uma separação real entre os grupos. Avaliamos essa qualidade sob duas perspectivas: significância estatística e acurácia de classificação.
10.4.1 Teste de Significância da Separação
Primeiro, precisamos verificar se as médias dos grupos são estatisticamente diferentes. A hipótese nula é que os vetores de médias populacionais são iguais, \(H_0: \boldsymbol{\mu}_1 = \boldsymbol{\mu}_2\). Se não pudermos rejeitar \(H_0\), a tentativa de separar os grupos não tem fundamento estatístico.
- Teste T² de Hotelling: Este é o teste multivariado análogo ao teste t para duas amostras. Ele testa diretamente a hipótese \(H_0: \boldsymbol{\mu}_1 = \boldsymbol{\mu}_2\) usando os dados multivariados originais.
- Teste t nos Escores Discriminantes: Uma abordagem alternativa e equivalente é realizar um teste t de duas amostras nas médias dos escores discriminantes, \(\bar{y}_1\) e \(\bar{y}_2\). A hipótese nula é \(H_0: E[Y_1] = E[Y_2]\). Se a função discriminante de Fisher de fato separa os grupos, então as médias dos escores projetados devem ser significativamente diferentes.
10.4.2 Acurácia da Classificação
A qualidade de uma regra de classificação é medida pela sua taxa de erro. Existem várias maneiras de estimar essa taxa.
A estimativa mais direta é a Taxa de Erro Aparente (APER), também conhecida como taxa de erro por resubstituição. Ela é calculada reclassificando as próprias observações da amostra de treinamento. Para isso, construímos uma matriz de confusão. Para dois grupos, esta matriz tem a seguinte forma:
| População Real | Classifica como \(\pi_1\) | Classifica como \(\pi_2\) | Total |
|---|---|---|---|
| \(\pi_1\) | \(n_{1|1}\) | \(n_{2|1}\) | \(n_1\) |
| \(\pi_2\) | \(n_{1|2}\) | \(n_{2|2}\) | \(n_2\) |
Onde: - \(n_1\) e \(n_2\) são os tamanhos das amostras dos grupos 1 e 2. - \(n_{i|j}\) é o número de observações alocadas no grupo \(i\) dado que eram provenientes da população \(j\).
Ou seja, os elementos na diagonal, \(n_{1|1}\) e \(n_{2|2}\), são as classificações corretas. Os elementos fora da diagonal, \(n_{2|1}\) e \(n_{1|2}\), são os erros de classificação.
Definição 10.3 A Taxa de Erro Aparente (APER) é a proporção do total de observações classificadas incorretamente na amostra de treinamento.
\[ APER = \frac{n_{2|1} + n_{1|2}}{n_1 + n_2} \]
A APER tende a subestimar a taxa de erro real, pois o modelo foi ajustado para otimizar a separação justamente nesses dados. Por essa razão, ela é considerada uma medida “otimista” da performance.
10.4.3 Método Holdout (Divisão Amostral)
Uma abordagem mais robusta para estimar a taxa de erro é o método holdout, ou divisão amostral. A ideia é dividir aleatoriamente o conjunto de dados original em dois subconjuntos:
- Amostra de Treinamento: Usada para construir o modelo discriminante (i.e., estimar os coeficientes das funções).
- Amostra de Validação (ou Teste): Usada para testar o modelo. As observações nesta amostra são classificadas usando a regra criada com a amostra de treinamento.
A taxa de erro calculada na amostra de validação é uma estimativa mais honesta e imparcial do desempenho do modelo em dados futuros, pois o modelo não “viu” essas observações durante o seu treinamento. A desvantagem do método holdout é que ele reduz o tamanho da amostra usada para treinar o modelo, o que pode ser um problema em datasets pequenos. Variações como a validação cruzada (k-fold cross-validation) são ainda mais robustas.
10.5 Generalização para K > 2 Grupos
As ideias da análise discriminante podem ser estendidas para o caso de \(K\) populações ou grupos.
10.5.1 Funções Discriminantes de Fisher
A abordagem de Fisher de maximizar a separação entre grupos enquanto minimiza a variação dentro deles é generalizada para encontrar múltiplas funções discriminantes. Para \(K\) grupos e \(p\) variáveis, podemos encontrar até \(s = \min(p, K-1)\) funções discriminantes.
Cada função é uma combinação linear das variáveis originais, \(y_j = \mathbf{a}_j'\mathbf{x}\), e elas são estimadas de forma hierárquica:
- A primeira função discriminante, \(y_1\), é a combinação linear que maximiza a separação entre as médias dos \(K\) grupos.
- A segunda função discriminante, \(y_2\), é a combinação linear, não correlacionada com \(y_1\), que melhor maximiza a separação restante.
- O processo continua até que \(s\) funções discriminantes sejam extraídas.
Essas funções fornecem um novo espaço de dimensão reduzida (um subespaço) que é otimizado para visualização e interpretação da separação dos grupos, como vimos no exemplo do dataset Iris.
10.5.2 Regras de Classificação e Fronteiras de Decisão
A abordagem probabilística de classificação também se generaliza. A regra é alocar uma nova observação \(\mathbf{x}\) ao grupo \(\pi_k\) para o qual a probabilidade a posteriori \(P(\pi_k | \mathbf{x})\) é máxima. Isso é equivalente a alocar \(\mathbf{x}\) ao grupo \(k\) que maximiza o escore \(\ln(p_k f_k(\mathbf{x}))\).
Para a LDA (Covariâncias Homogêneas):
Com \(\mathbf{\Sigma}_1 = \dots = \mathbf{\Sigma}_K = \mathbf{\Sigma}_{pooled}\), o escore para o grupo \(k\) (ignorando termos constantes) é linear em \(\mathbf{x}\):
\[ d_k^L(\mathbf{x}) = \mathbf{x}' \mathbf{S}_{pooled}^{-1} \bar{\mathbf{x}}_k - \frac{1}{2} \bar{\mathbf{x}}_k' \mathbf{S}_{pooled}^{-1} \bar{\mathbf{x}}_k + \ln(p_k) \]
A fronteira de decisão entre quaisquer dois grupos \(\pi_i\) e \(\pi_j\) é o conjunto de pontos onde seus escores são iguais: \(d_i^L(\mathbf{x}) = d_j^L(\mathbf{x})\). Isso define um hiperplano. O espaço p-dimensional é, portanto, particionado em \(K\) regiões de decisão convexas.
Para a QDA (Covariâncias Heterogêneas):
Quando as matrizes de covariância são diferentes, o escore para o grupo \(k\) permanece quadrático:
\[ d_k^Q(\mathbf{x}) = -\frac{1}{2} \ln|\mathbf{S}_k| - \frac{1}{2}(\mathbf{x} - \bar{\mathbf{x}}_k)' \mathbf{S}_k^{-1} (\mathbf{x} - \bar{\mathbf{x}}_k) + \ln(p_k) \]
A fronteira de decisão entre dois grupos \(\pi_i\) e \(\pi_j\) é definida por \(d_i^Q(\mathbf{x}) = d_j^Q(\mathbf{x})\), que é uma equação quadrática. As fronteiras são superfícies cônicas (elipses, parábolas, hipérboles), e as regiões de decisão não são necessariamente convexas.