A Análise Fatorial (AF) é uma técnica estatística poderosa usada para identificar estruturas latentes (fatores) subjacentes a um conjunto de variáveis observadas. No entanto, a solução matemática inicial de uma AF raramente é interpretável. É aqui que a rotação fatorial se torna a etapa mais crítica do processo. A rotação transforma a matriz de cargas fatoriais inicial em uma solução mais simples e teoricamente mais significativa, sem alterar as propriedades matemáticas fundamentais da solução.
Este documento oferece um exemplo prático e didático, totalmente focado em demonstrar o impacto das diferentes estratégias de rotação. Usaremos o software R e o clássico conjunto de dados bfi (Big Five Inventory) do pacote psych.
Objetivos:
Comparar métodos de extração: Componentes Principais (PAF) e Máxima Verossimilhança (ML).
Demonstrar a dificuldade de interpretar uma solução fatorial não rotacionada.
Aplicar e interpretar uma rotação ortogonal (Varimax), que assume fatores não correlacionados.
Aplicar e interpretar uma rotação oblíqua (Promax), que permite a correlação entre os fatores.
Discutir como a escolha da rotação afeta a interpretação final e a validade teórica dos resultados.
14.1 Passo 1: Análise Descritiva e Adequação dos Dados
Primeiro, carregamos os pacotes necessários e o conjunto de dados bfi. Este dataset contém respostas de 2800 indivíduos a 25 itens de personalidade.
Código
# Carregar pacoteslibrary(psych)library(ggplot2)library(dplyr)library(tidyr)library(corrplot)# Carregar os dados do Big Five Inventorydata(bfi, package ="psych")# Selecionar apenas as 25 variáveis de itens de personalidadebfi_items <- bfi[, 1:25]# Remover linhas com dados ausentes para simplificarbfi_complete <-na.omit(bfi_items)knitr::kable(head(bfi_complete))
Tabela 14.1: Exemplo de respostas no banco de dados Big Five
A1
A2
A3
A4
A5
C1
C2
C3
C4
C5
E1
E2
E3
E4
E5
N1
N2
N3
N4
N5
O1
O2
O3
O4
O5
61617
2
4
3
4
4
2
3
3
4
4
3
3
3
4
4
3
4
2
2
3
3
6
3
4
3
61618
2
4
5
2
5
5
4
4
3
4
1
1
6
4
3
3
3
3
5
5
4
2
4
3
3
61620
5
4
5
4
4
4
5
4
2
5
2
4
4
4
5
4
5
4
2
3
4
2
5
5
2
61621
4
4
6
5
5
4
4
3
5
5
5
3
4
4
4
2
5
2
4
1
3
3
4
3
5
61622
2
3
3
4
5
4
4
5
3
2
2
2
5
4
5
2
3
4
4
3
3
3
4
3
3
61623
6
6
5
6
5
6
6
6
1
3
2
1
6
5
6
3
5
2
2
3
4
3
5
6
1
As 25 variáveis correspondem a 5 itens para cada um dos traços do “Big Five”:
A1-A5: Amabilidade (Agreeableness)
C1-C5: Conscienciosidade (Conscientiousness)
E1-E5: Extroversão (Extraversion)
N1-N5: Neuroticismo (Neuroticism)
O1-O5: Abertura à Experiência (Openness)
A hipótese teórica é que os 5 itens que medem o mesmo traço (e.g., N1 a N5) estarão altamente correlacionados entre si e se agruparão em um único fator latente (Neuroticismo).
Uma boa prática é verificar se os dados são fatorizáveis. Para isso, podemos usar o teste de Bartlett e a medida KMO.
Código
# Teste de Bartlettbartlett_test <-cortest.bartlett(bfi_complete)
R was not square, finding R from data
Código
# Teste KMOkmo_test <-KMO(bfi_complete)# Exibindo os resultados de forma concisacat("Teste de Bartlett: p-valor =", bartlett_test$p.value, "\n")
O p-valor de Bartlett próximo de zero e o KMO de 0.85 (“meritório”) sugerem que os dados têm correlações suficientes para justificar uma análise fatorial.
14.2 Passo 2: Extração Inicial dos Fatores e Escolha do Número de Fatores
Antes de rotacionar, precisamos extrair os fatores. Dois métodos comuns são a Fatoração do Eixo Principal (ou “componentes principais” para o modelo fatorial) e a Máxima Verossimilhança. Vamos extrair 5 fatores usando ambos os métodos (sem rotação) para ver a solução inicial.
Código
# Extração via Fatoração do Eixo Principal (Principal Axis Factoring)fa_pa <-fa(bfi_complete, nfactors =5, rotate ="none", fm ="pa")cat("Cargas - Fatoração do Eixo Principal (PA):\n")
As duas soluções iniciais são numericamente diferentes, mas conceitualmente iguais: são ininterpretáveis. Um primeiro fator geral domina, e as variáveis se distribuem de forma confusa nos demais. Isso reforça a necessidade da rotação.
Para determinar o número de fatores a extrair de forma mais objetiva, usamos a Análise Paralela.
Código
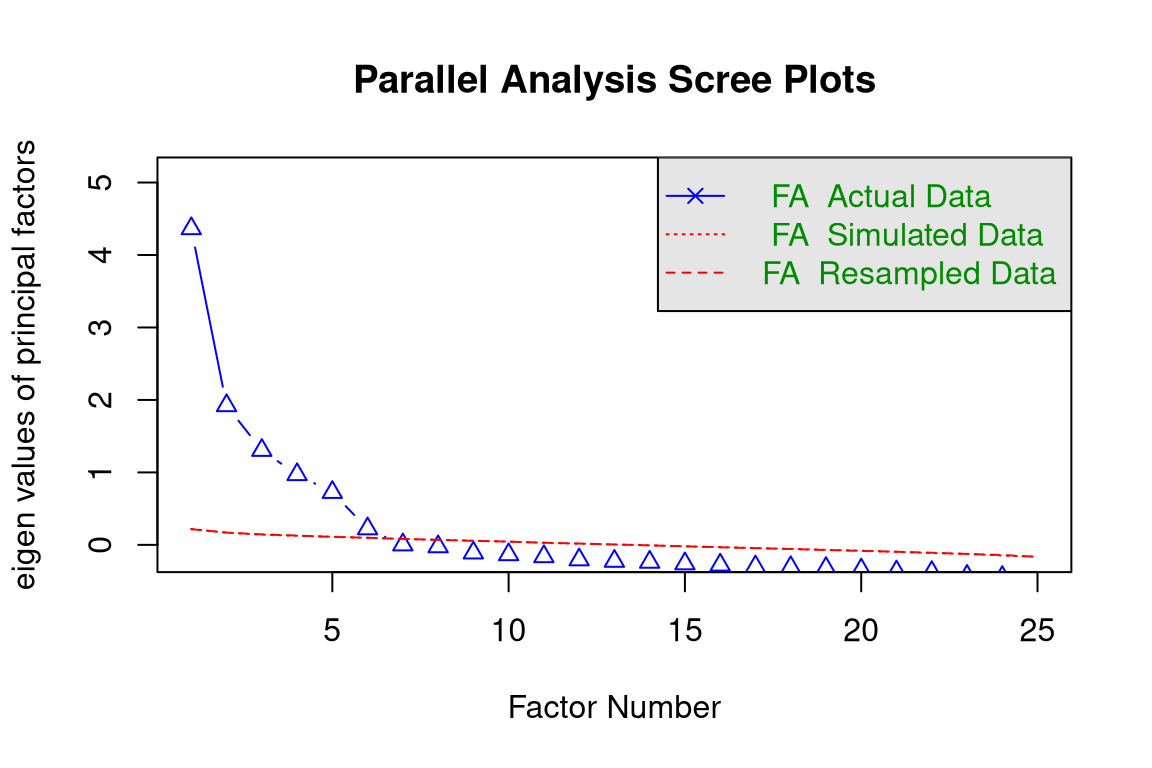
fa.parallel(bfi_complete, fa ="fa", fm ="pa")
Parallel analysis suggests that the number of factors = 6 and the number of components = NA
Figura 14.1: Análise Paralela sugerindo a extração de 6 fatores.
A Análise Paralela (Figura 14.1) sugere 6 fatores. No entanto, como nosso objetivo é testar a teoria dos Big Five, prosseguiremos com a extração de 5 fatores, uma decisão comum quando a teoria é forte.
14.3 Passo 3: Rotação Ortogonal (Varimax)
A rotação Varimax “limpa” a estrutura sob a suposição de que os fatores não são correlacionados entre si.
A estrutura agora é muito mais “simples” e alinhada com a teoria. Podemos visualizar essa transformação de forma clara comparando o círculo de correlações antes e depois da rotação.
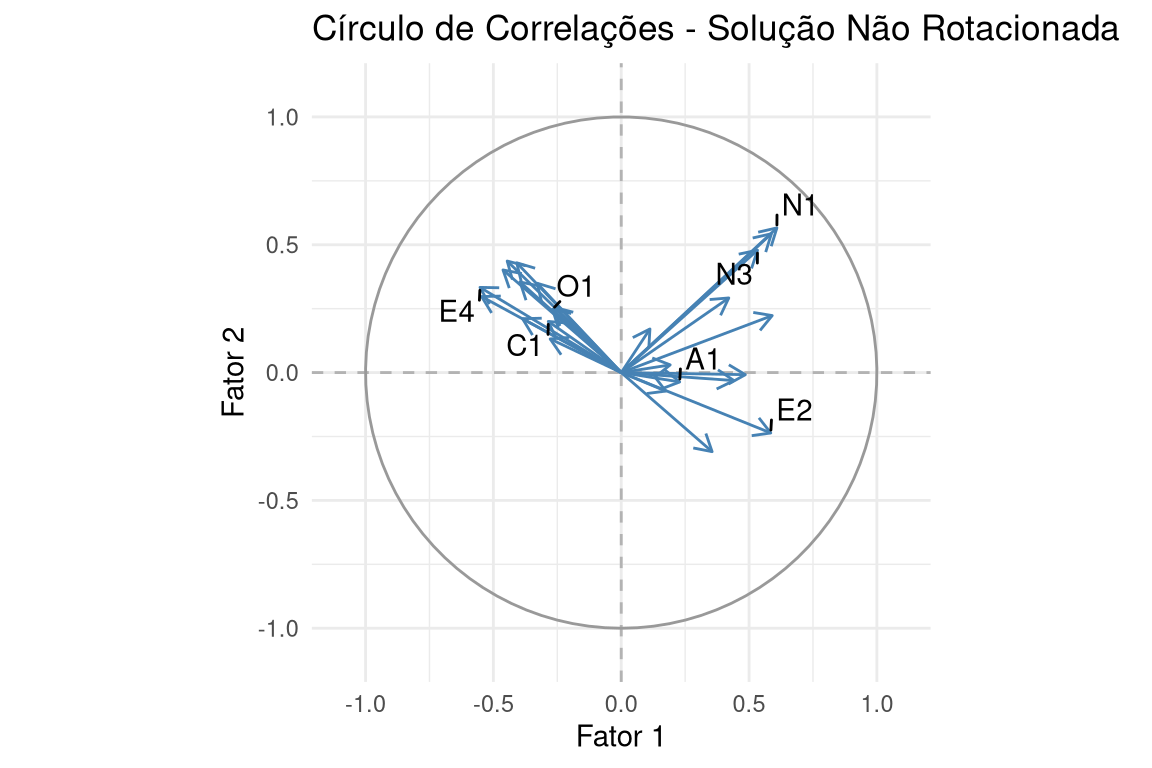
Primeiro, a solução não rotacionada (Figura 14.2). Note como as variáveis (vetores) se espalham pelo espaço fatorial sem um padrão claro. É difícil traçar os eixos (fatores) de forma que representem grupos distintos de variáveis.
Código
library(ggrepel)# Extrair cargas da solução NÃO ROTACIONADA (ml) para um dataframeloadings_unrotated_df <-as.data.frame(unclass(fa_ml$loadings))loadings_unrotated_df$Variable <-rownames(loadings_unrotated_df)# Selecionar algumas variáveis para anotar e evitar poluiçãovars_to_label <-c("N1", "N3", "E2", "E4", "A1", "C1", "O1")annotations_df_unrotated <- loadings_unrotated_df %>%filter(Variable %in% vars_to_label)# Criar dados para o círculo unitáriocircle <-data.frame(angle =seq(-pi, pi, length =100),x =sin(seq(-pi, pi, length =100)),y =cos(seq(-pi, pi, length =100)))# Gerar o gráfico com ggplot2ggplot(data = loadings_unrotated_df, aes(x = ML1, y = ML2)) +geom_hline(yintercept =0, linetype ="dashed", color ="gray70") +geom_vline(xintercept =0, linetype ="dashed", color ="gray70") +geom_path(data = circle, aes(x = x, y = y), inherit.aes =FALSE, color ="gray60") +geom_segment(aes(x =0, y =0, xend = ML1, yend = ML2),arrow =arrow(length =unit(0.1, "inches")),color ="steelblue") +geom_text_repel(data = annotations_df_unrotated, aes(label = Variable), min.segment.length =0) +coord_fixed(ratio =1, xlim =c(-1.1, 1.1), ylim =c(-1.1, 1.1)) +labs(title ="Círculo de Correlações - Solução Não Rotacionada",x ="Fator 1",y ="Fator 2") +theme_minimal()
Figura 14.2: Círculo de correlações da solução não rotacionada. Os vetores não estão alinhados com os eixos.
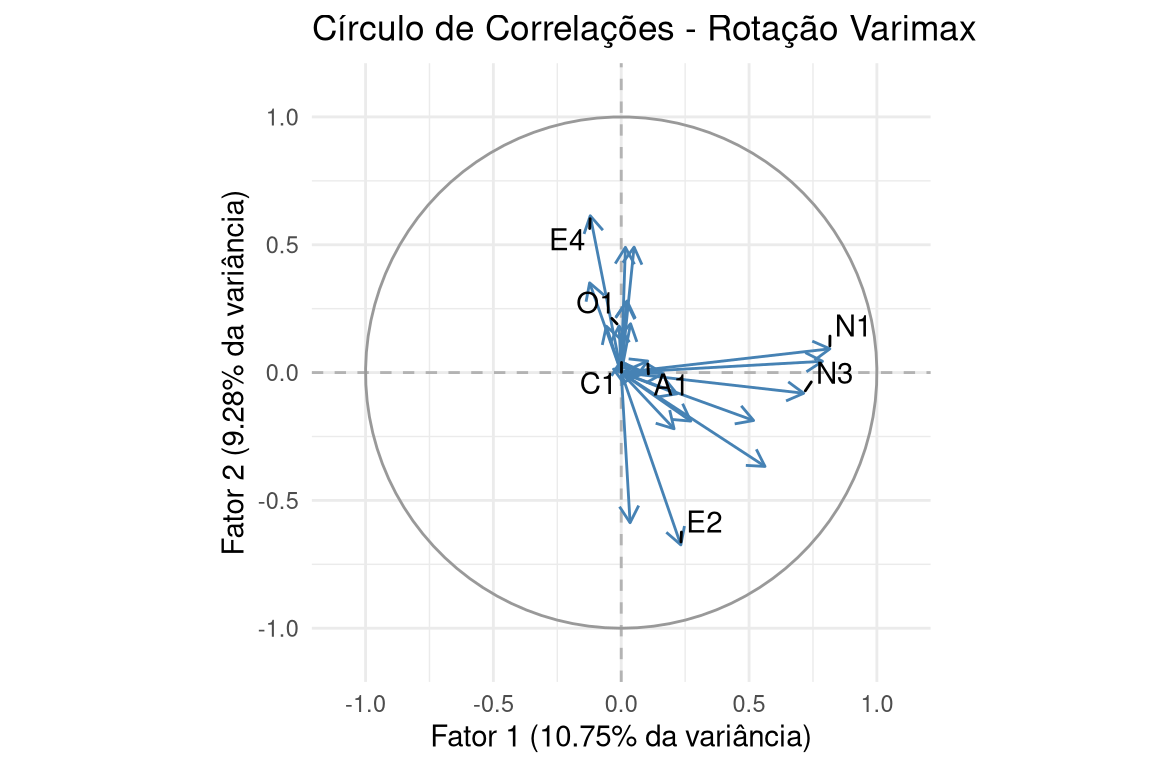
Agora, veja o resultado após a rotação Varimax (Figura 14.3). A rotação funcionou como um ajuste dos eixos, alinhando-os com os agrupamentos de variáveis.
Código
# Extrair cargas da solução ROTACIONADA (Varimax) para um dataframeloadings_rotated_df <-as.data.frame(unclass(fa_varimax$loadings))loadings_rotated_df$Variable <-rownames(loadings_rotated_df)# Selecionar as mesmas variáveis para anotarannotations_df_rotated <- loadings_rotated_df %>%filter(Variable %in% vars_to_label)# Calcular a variância explicada para os eixosss_loadings <-colSums(fa_varimax$loadings^2)prop_variance <- ss_loadings /ncol(bfi_complete)xlab_text <-sprintf("Fator 1 (%.2f%% da variância)", prop_variance[1] *100)ylab_text <-sprintf("Fator 2 (%.2f%% da variância)", prop_variance[2] *100)# Gerar o gráfico com ggplot2ggplot(data = loadings_rotated_df, aes(x = Factor1, y = Factor2)) +geom_hline(yintercept =0, linetype ="dashed", color ="gray70") +geom_vline(xintercept =0, linetype ="dashed", color ="gray70") +geom_path(data = circle, aes(x = x, y = y), inherit.aes =FALSE, color ="gray60") +geom_segment(aes(x =0, y =0, xend = Factor1, yend = Factor2),arrow =arrow(length =unit(0.1, "inches")),color ="steelblue") +geom_text_repel(data = annotations_df_rotated, aes(label = Variable), min.segment.length =0) +coord_fixed(ratio =1, xlim =c(-1.1, 1.1), ylim =c(-1.1, 1.1)) +labs(title ="Círculo de Correlações - Rotação Varimax",x = xlab_text,y = ylab_text) +theme_minimal()
Figura 14.3: Círculo de correlações após a rotação Varimax. A rotação alinhou os vetores com os eixos, revelando uma estrutura simples.
O resultado é uma “estrutura simples”, onde os itens de Neuroticismo (como N1 e N3) carregam quase exclusivamente no Fator 1 (correlação próxima de 1 ou -1 em um eixo e de 0 no outro), e os itens de Extroversão (como E2 e E4) carregam no Fator 2. A interpretação se torna direta.
14.4 Passo 4: Rotação Oblíqua (Promax)
A rotação Promax é mais flexível, pois permite que os fatores sejam correlacionados. Isso costuma ser mais realista em psicologia.
Código
# Análise Fatorial com rotação Promax (oblíqua)fa_promax <-fa(bfi_complete, nfactors =5, rotate ="promax", fm ="pa")
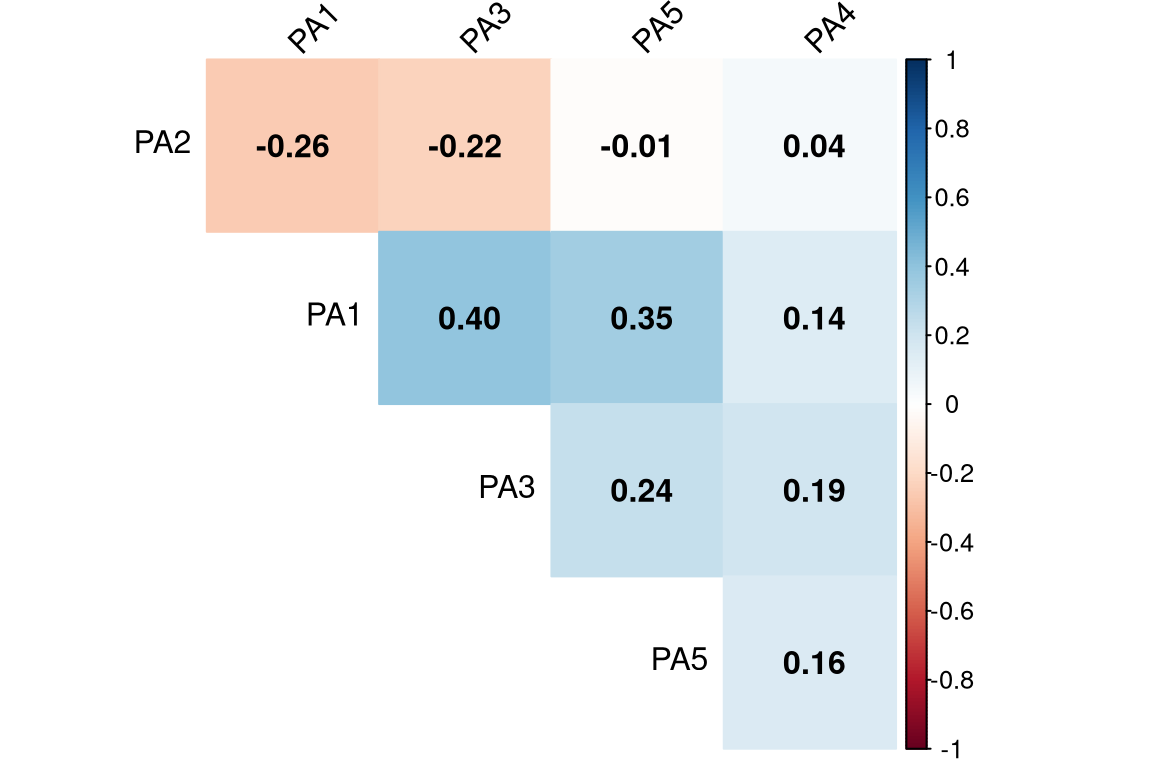
# Visualização da matriz de correlaçãocorrplot(factor_correlations, method ="color", type ="upper", addCoef.col ="black", tl.col ="black", tl.srt =45, diag =FALSE)
Figura 14.4: Correlações entre os fatores da solução Promax.
A matriz de correlação (Figura 14.4) mostra que Neuroticismo (ML1) se correlaciona negativamente com Conscienciosidade (ML3) (-0.33) e Extroversão (ML2) (-0.24). Essas relações são teoricamente plausíveis e seriam perdidas em uma rotação ortogonal.
14.5 Conclusão: Qual Rotação Escolher?
Solução Não Rotacionada: É apenas um ponto de partida matemático. Dificilmente é possível tirar interpretações úteis dela.
Rotação Ortogonal (Varimax): É a melhor escolha quando há fortes razões teóricas para acreditar que os fatores são independentes. Oferece uma solução mais simples (parcimoniosa).
Rotação Oblíqua (Promax): É uma escolha mais realista nas ciências sociais. A decisão final deve ser baseada na matriz de correlação dos fatores. Se as correlações forem substanciais, a solução oblíqua é superior.
Neste exemplo, a solução Promax (oblíqua) é a mais apropriada. Ela não apenas recupera a estrutura dos Big Five, mas também fornece insights sobre como esses traços se relacionam, oferecendo uma visão mais rica e fiel da realidade psicológica.