Neste exemplo, vamos aplicar a Análise de Correspondência (CA) a um conjunto de dados real para explorar a associação entre duas variáveis categóricas. Usaremos o famoso conjunto de dados HairEyeColor, que contém as frequências de combinações de cor de cabelo e cor dos olhos. O ponto de partida é uma tabela de contingência. Carregamos os dados e os formatamos como uma tabela onde as linhas representam a cor do cabelo e as colunas, a cor dos olhos.
Código
import pandas as pdimport numpy as np# Dados do HairEyeColor (soma de homens e mulheres)# Fonte: Fisher, R. A. (1940) The precision of discriminant functions.# Annals of Eugenics, 10, 422-429.data = {'Brown': [68, 119, 26, 7],'Blue': [20, 84, 17, 94],'Hazel': [15, 54, 14, 10],'Green': [5, 29, 14, 16]}index = ['Black', 'Brown', 'Red', 'Blond']columns = ['Brown', 'Blue', 'Hazel', 'Green']N = pd.DataFrame(data, index=index, columns=columns)N
Tabela 18.1: Tabela de contingência: Cor do Cabelo vs. Cor dos Olhos
Brown
Blue
Hazel
Green
Black
68
20
15
5
Brown
119
84
54
29
Red
26
17
14
14
Blond
7
94
10
16
A tabela acima é a nossa matriz de contagens \(\mathbf{N}\).
18.1 Análise e Decomposição das Matrizes
A partir da tabela de contagens, calculamos as matrizes fundamentais para a CA. Primeiro, dividimos cada contagem pelo total geral para obter a matriz de proporções, ou matriz de correspondência (P). Em seguida, calculamos os perfis médios (marginais de linha \(\mathbf{r}\) e de coluna \(\mathbf{c}\)) para obter a matriz de independência (E), que representa as proporções esperadas se não houvesse associação entre as variáveis.
Código
P = N / N.values.sum()P.style.format("{:.4f}")r = P.sum(axis=1)c = P.sum(axis=0)E = pd.DataFrame(np.outer(r, c), index=N.index, columns=N.columns)
Matriz de correspondência (P)
Brown
Blue
Hazel
Green
Black
0.1149
0.0338
0.0253
0.0084
Brown
0.2010
0.1419
0.0912
0.0490
Red
0.0439
0.0287
0.0236
0.0236
Blond
0.0118
0.1588
0.0169
0.0270
Matriz de independência (E)
Brown
Blue
Hazel
Green
Black
0.0678
0.0663
0.0287
0.0197
Brown
0.1795
0.1755
0.0759
0.0522
Red
0.0446
0.0436
0.0188
0.0130
Blond
0.0797
0.0779
0.0337
0.0232
A diferença entre \(\mathbf{P}\) e \(\mathbf{E}\) é a associação que a CA busca explicar. Para isso, decompomos essa associação em “tabelas de fatores” ortogonais (\(\mathbf{T}_1, \mathbf{T}_2, \dots\)). A reconstrução da matriz original é dada por:
Abaixo, calculamos as matrizes para os dois primeiros e mais importantes fatores.
Código
# Realizando a análise de correspondênciaS = np.diag(r**-0.5) @ (P - E).values @ np.diag(c**-0.5)U, s, Vt = np.linalg.svd(S, full_matrices=False)V = Vt.T# Função para calcular a tabela de um fator kdef get_factor_table(k, U, s, V, r, c): R_hat_k = s[k] * np.outer(U[:, k], V[:, k]) T_k = np.diag(r**0.5) @ R_hat_k @ np.diag(c**0.5)return pd.DataFrame(T_k, index=N.index, columns=N.columns)# Calculando as tabelas dos fatoresT1 = get_factor_table(0, U, s, V, r, c)T2 = get_factor_table(1, U, s, V, r, c)# Matrizes reconstruídasP_hat1 = E + T1P_hat2 = E + T1 + T2
Matriz do primeiro fator (T1)
Brown
Blue
Hazel
Green
Black
0.0368
-0.0401
0.0067
-0.0035
Brown
0.0287
-0.0312
0.0052
-0.0027
Red
0.0062
-0.0068
0.0011
-0.0006
Blond
-0.0717
0.0780
-0.0131
0.0069
Matriz do segundo fator (T2)
Brown
Blue
Hazel
Green
Black
0.0086
0.0079
-0.0069
-0.0096
Brown
-0.0035
-0.0032
0.0028
0.0039
Red
-0.0084
-0.0077
0.0068
0.0094
Blond
0.0033
0.0030
-0.0026
-0.0037
18.2 Visualização e Interpretação
Para entender o que esses fatores representam, recorremos à visualização. Os heatmaps, por exemplo, são uma excelente forma de comparar a matriz original com as suas reconstruções.
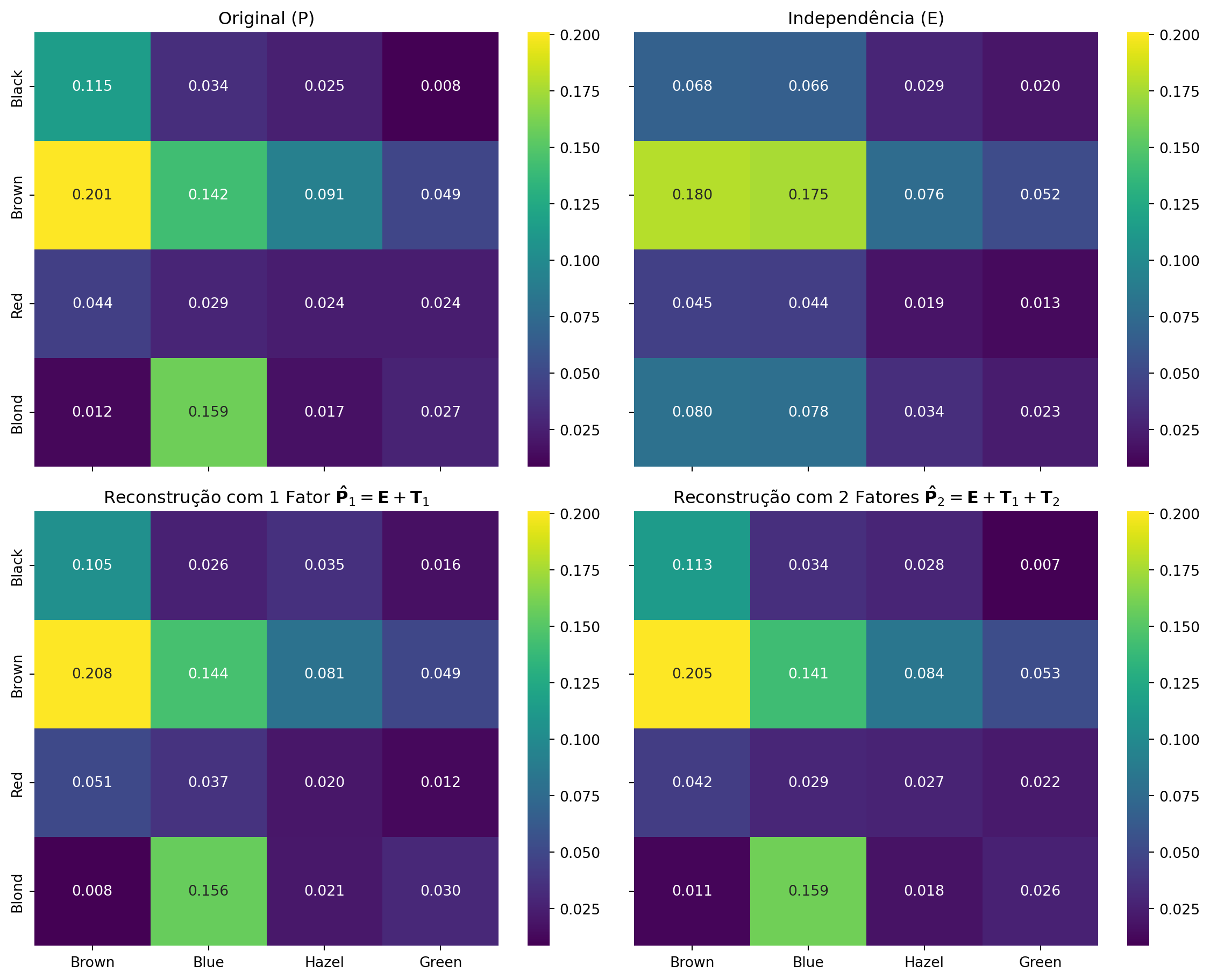
Figura 18.1: Comparação da reconstrução da matriz P
O mapa de calor da reconstrução com 2 fatores já é visualmente muito similar ao original, mostrando que as duas primeiras dimensões capturam a maior parte da associação. Se adicionarmos o terceiro (e último) par de fatores, isto é \(\mathbf{P} - \mathbf{E} = \mathbf{T}_1 + \mathbf{T}_2 + \mathbf{T}_3\), teriamos uma reconstrução perfeita.
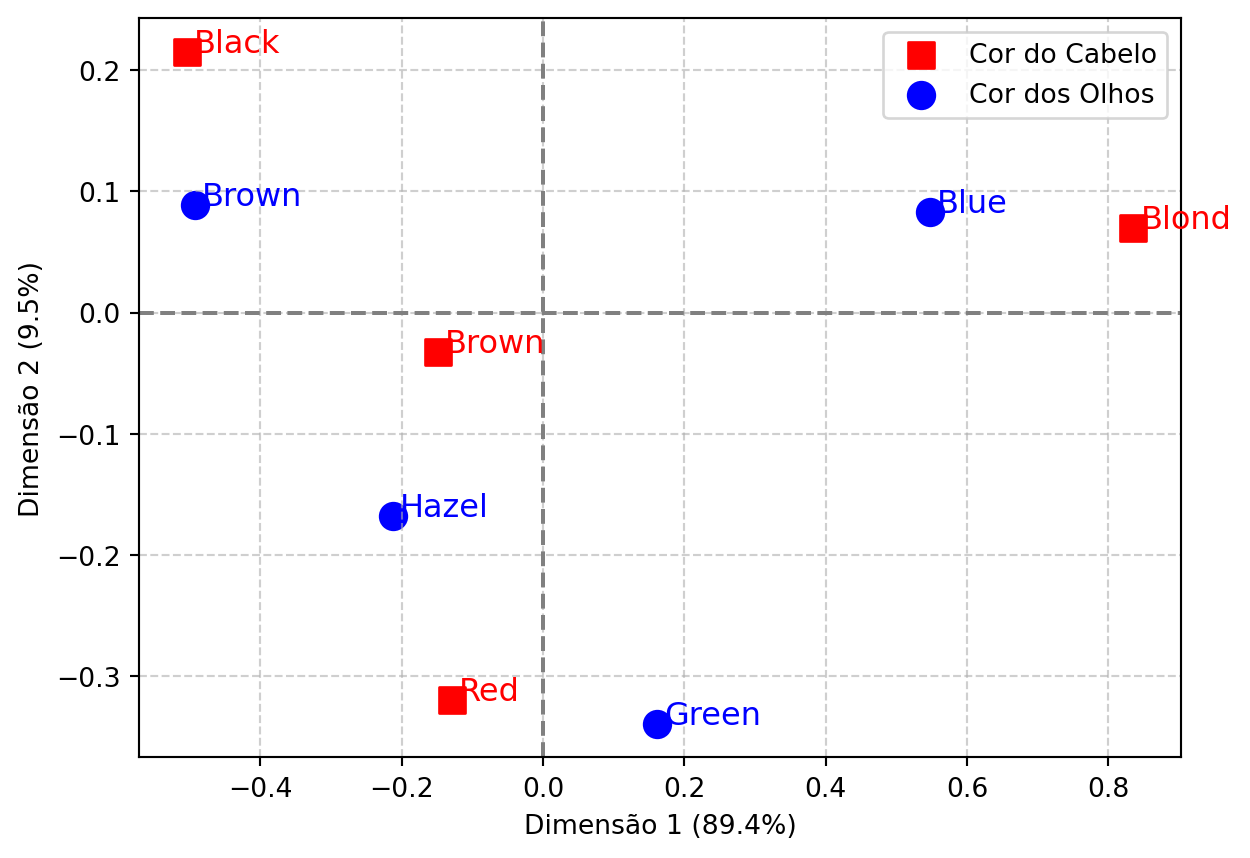
Finalmente, o biplot nos permite interpretar a natureza dessa associação. Ele projeta as categorias de linha e coluna em um espaço de baixa dimensão (geralmente 2D), onde a proximidade entre pontos indica uma associação mais forte.
Código
# Coordenadas principaisLambda = np.diag(s)F = np.diag(r**-0.5) @ U @ LambdaG = np.diag(c**-0.5) @ V @ LambdaF_df = pd.DataFrame(F[:, :2], index=N.index, columns=['Dim 1', 'Dim 2'])G_df = pd.DataFrame(G[:, :2], index=N.columns, columns=['Dim 1', 'Dim 2'])# Inércia explicadatotal_inertia = np.sum(s**2)inertia_explained = (s**2) / total_inertia# Plotfig, ax = plt.subplots(figsize=(7, 5))# Pontos das linhas (cor de cabelo)ax.scatter(F_df['Dim 1'], F_df['Dim 2'], c='red', marker='s', s=100, label='Cor do Cabelo')for txt in F_df.index: ax.text(F_df.loc[txt, 'Dim 1'] +0.01, F_df.loc[txt, 'Dim 2'], txt, color='red', fontsize=12)# Pontos das colunas (cor dos olhos)ax.scatter(G_df['Dim 1'], G_df['Dim 2'], c='blue', marker='o', s=100, label='Cor dos Olhos')for txt in G_df.index: ax.text(G_df.loc[txt, 'Dim 1'] +0.01, G_df.loc[txt, 'Dim 2'], txt, color='blue', fontsize=12)ax.axhline(0, color='gray', linestyle='--')ax.axvline(0, color='gray', linestyle='--')ax.grid(True, linestyle='--', alpha=0.6)ax.set_xlabel(f"Dimensão 1 ({inertia_explained[0]:.1%})")ax.set_ylabel(f"Dimensão 2 ({inertia_explained[1]:.1%})")ax.legend()plt.show()
Figura 18.2: Biplot da associação entre cor de cabelo e cor dos olhos
A interpretação visual do biplot é poderosa, mas para uma análise rigorosa, devemos examinar as métricas de qualidade e contribuição que discutimos na Capítulo 11.
Código
# Distances to origin (squared) for full spacerow_dist2 = np.sum(F**2, axis=1)col_dist2 = np.sum(G**2, axis=1)# Point inertias (contribution to total inertia)row_inertia = r.values * row_dist2col_inertia = c.values * col_dist2# Quality of representation (cos2) for the first 2 dimsrow_cos2 = F[:, :2]**2/ row_dist2[:, np.newaxis]col_cos2 = G[:, :2]**2/ col_dist2[:, np.newaxis]# Relative contributions to the first 2 dims' inertiarow_contrib = (np.diag(r.values) @ F[:, :2]**2) / (s[:2]**2)col_contrib = (np.diag(c.values) @ G[:, :2]**2) / (s[:2]**2)# Create pandas DataFrames for nice displayrow_metrics = pd.DataFrame({'Inércia': row_inertia,'cos2_mapa': row_cos2.sum(axis=1),'ctr_dim1': row_contrib[:, 0],'ctr_dim2': row_contrib[:, 1]}, index=N.index)row_metrics.index.name ="Cor do Cabelo"col_metrics = pd.DataFrame({'Inércia': col_inertia,'cos2_mapa': col_cos2.sum(axis=1),'ctr_dim1': col_contrib[:, 0],'ctr_dim2': col_contrib[:, 1]}, index=N.columns)col_metrics.index.name ="Cor dos Olhos"# Displaying with stylestyled_rows = row_metrics.style.format({'Inércia': '{:.4f}','cos2_mapa': '{:.3f}','ctr_dim1': '{:.1%}','ctr_dim2': '{:.1%}'}).set_caption("Métricas para Cor do Cabelo")styled_cols = col_metrics.style.format({'Inércia': '{:.4f}','cos2_mapa': '{:.3f}','ctr_dim1': '{:.1%}','ctr_dim2': '{:.1%}'}).set_caption("Métricas para Cor dos Olhos")from IPython.display import displaydisplay(styled_rows)display(styled_cols)
Tabela 18.2: Métricas de interpretação para as categorias de cabelo e olhos.
(a) Métricas para Cor do Cabelo
Inércia
cos2_mapa
ctr_dim1
ctr_dim2
Cor do Cabelo
Black
0.0554
0.990
22.2%
37.9%
Brown
0.0123
0.906
5.1%
2.3%
Red
0.0151
0.945
1.0%
55.1%
Blond
0.1508
1.000
71.7%
4.7%
(b) Métricas para Cor dos Olhos
Inércia
cos2_mapa
ctr_dim1
ctr_dim2
Cor dos Olhos
Brown
0.0931
0.998
43.1%
13.0%
Blue
0.1113
1.000
52.1%
11.2%
Hazel
0.0131
0.879
3.4%
19.8%
Green
0.0161
0.948
1.4%
55.9%
O biplot e as métricas quantitativas nos permitem construir uma interpretação detalhada:
Qualidade da Representação (cos2_mapa): As tabelas mostram que a maioria das categorias tem uma excelente qualidade de representação no mapa (cos2 > 0.8), com destaque para Black, Blond e Blue. A categoria Hazel (olhos) é a única com uma representação mais fraca, portanto sua posição no mapa é menos precisa e deve ser interpretada com cautela.
Significado da Dimensão 1 (89.4% da inércia):
Contribuições (ctr_dim1): As tabelas de contribuição mostram que este eixo é definido primariamente pelas cores de cabelo Black e Blond e pelas cores de olho Brown e Blue.
Interpretação: A Dimensão 1 representa o contraste “cores escuras vs. claras”. À esquerda do eixo, temos as categorias de cabelo e olhos escuros; à direita, as claras. Isso confirma que a associação mais forte nos dados é entre cabelo/olhos escuros e cabelo/olhos claros.
Significado da Dimensão 2 (9.5% da inércia):
Contribuições (ctr_dim2): A segunda dimensão é majoritariamente definida pelo cabelo Red e pelos olhos Green e Hazel.
Interpretação: Este eixo secundário separa as cores “intermediárias”, contrastando o cabelo ruivo e os olhos verdes/avelã das demais categorias.
Pontos mais influentes (Inércia): As categorias com maior inércia, e portanto maior impacto na associação geral, são Blond (cabelo) e Blue (olhos). Seus perfis são os que mais se desviam da média, impulsionando a maior parte da estrutura encontrada.
Em resumo, a análise quantitativa confirma e aprofunda a interpretação visual. Ela revela uma estrutura muito clara nos dados: a dimensão mais forte de associação é o gradiente de cores claras para escuras, seguida por uma dimensão secundária que isola as combinações de cabelo ruivo com olhos verdes/avelã.