Código
library(tidyverse)
library(FactoMineR)
library(factoextra)
library(patchwork)A Análise de Correspondência Múltipla (ACM) é uma extensão da Análise de Correspondência Simples (ACS) para mais de duas variáveis categóricas. Nesta seção, vamos explorar a ACM através de dois exemplos práticos que ilustram as duas principais abordagens da técnica:
poison para ilustrar este caso.tea para ilustrar esta abordagem.Para as análises, usaremos os pacotes R FactoMineR para os cálculos e factoextra para as visualizações.
library(tidyverse)
library(FactoMineR)
library(factoextra)
library(patchwork)poisonEsta abordagem é mais útil quando temos um número de observações pequeno o suficiente para que a interpretação da posição de cada indivíduo (ou de pequenos grupos de indivíduos) seja viável e informativa. Frequentemente, esse tipo de análise pode servir como um pré-processamento para uma análise secundária, como o agrupamento de indivíduos.
Vamos utilizar o conjunto de dados poison, disponível no pacote FactoMineR. Ele contém dados sobre 55 crianças que foram diagnosticadas com intoxicação alimentar. As variáveis registram os sintomas apresentados (Nausea, Vomiting, Diarrhoea, etc.) e os alimentos consumidos (Potato, Fish, Mayo, etc.). O objetivo é identificar perfis de sintomas e associá-los aos alimentos ingeridos.
data(poison)
# Transformar em tibble para melhor visualização
poison_df <- as_tibble(poison)
# Exibir as primeiras linhas e a estrutura
knitr::kable(head(poison_df))
# Verificar a estrutura dos dados (fatores)
str(poison_df)tibble [55 × 15] (S3: tbl_df/tbl/data.frame)
$ Age : int [1:55] 9 5 6 9 7 72 5 10 5 11 ...
$ Time : int [1:55] 22 0 16 0 14 9 16 8 20 12 ...
$ Sick : Factor w/ 2 levels "Sick_n","Sick_y": 2 1 2 1 2 2 2 2 2 2 ...
$ Sex : Factor w/ 2 levels "F","M": 1 1 1 1 2 2 1 1 2 2 ...
$ Nausea : Factor w/ 2 levels "Nausea_n","Nausea_y": 2 1 1 1 1 1 1 2 2 1 ...
$ Vomiting : Factor w/ 2 levels "Vomit_n","Vomit_y": 1 1 2 1 2 1 2 2 1 2 ...
$ Abdominals: Factor w/ 2 levels "Abdo_n","Abdo_y": 2 1 2 1 2 2 2 2 2 1 ...
$ Fever : Factor w/ 2 levels "Fever_n","Fever_y": 2 1 2 1 2 2 2 2 2 2 ...
$ Diarrhae : Factor w/ 2 levels "Diarrhea_n","Diarrhea_y": 2 1 2 1 2 2 2 2 2 2 ...
$ Potato : Factor w/ 2 levels "Potato_n","Potato_y": 2 2 2 2 2 2 2 2 2 2 ...
$ Fish : Factor w/ 2 levels "Fish_n","Fish_y": 2 2 2 2 2 1 2 2 2 2 ...
$ Mayo : Factor w/ 2 levels "Mayo_n","Mayo_y": 2 2 2 1 2 2 2 2 2 2 ...
$ Courgette : Factor w/ 2 levels "Courg_n","Courg_y": 2 2 2 2 2 2 2 2 2 2 ...
$ Cheese : Factor w/ 2 levels "Cheese_n","Cheese_y": 2 1 2 2 2 2 2 2 2 2 ...
$ Icecream : Factor w/ 2 levels "Icecream_n","Icecream_y": 2 2 2 2 2 2 2 2 2 2 ...| Age | Time | Sick | Sex | Nausea | Vomiting | Abdominals | Fever | Diarrhae | Potato | Fish | Mayo | Courgette | Cheese | Icecream |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 9 | 22 | Sick_y | F | Nausea_y | Vomit_n | Abdo_y | Fever_y | Diarrhea_y | Potato_y | Fish_y | Mayo_y | Courg_y | Cheese_y | Icecream_y |
| 5 | 0 | Sick_n | F | Nausea_n | Vomit_n | Abdo_n | Fever_n | Diarrhea_n | Potato_y | Fish_y | Mayo_y | Courg_y | Cheese_n | Icecream_y |
| 6 | 16 | Sick_y | F | Nausea_n | Vomit_y | Abdo_y | Fever_y | Diarrhea_y | Potato_y | Fish_y | Mayo_y | Courg_y | Cheese_y | Icecream_y |
| 9 | 0 | Sick_n | F | Nausea_n | Vomit_n | Abdo_n | Fever_n | Diarrhea_n | Potato_y | Fish_y | Mayo_n | Courg_y | Cheese_y | Icecream_y |
| 7 | 14 | Sick_y | M | Nausea_n | Vomit_y | Abdo_y | Fever_y | Diarrhea_y | Potato_y | Fish_y | Mayo_y | Courg_y | Cheese_y | Icecream_y |
| 72 | 9 | Sick_y | M | Nausea_n | Vomit_n | Abdo_y | Fever_y | Diarrhea_y | Potato_y | Fish_n | Mayo_y | Courg_y | Cheese_y | Icecream_y |
As variáveis Age e Sex serão tratadas como suplementares, o que significa que elas não participarão da construção dos eixos fatoriais, mas serão projetadas no mapa para auxiliar na interpretação. Além delas, as variáveis binárias Sick e Sex também serão tratadas como suplementares. A variável Sick indica se o indivíduo foi diagnosticado com intoxicação alimentar. Ou seja, essa variável é importantíssima para a análise.
# Executar a ACM
# graph = FALSE evita que o gráfico padrão do FactoMineR seja plotado imediatamente
mca_poison <- MCA(poison, quanti.sup = 1:2, quali.sup = 3:4, graph = FALSE)
# O scree plot mostra a inércia de cada dimensão
# A linha vermelha indica a inércia média esperada se não houvesse associação
fviz_screeplot(mca_poison,
repel=TRUE,
addlabels = TRUE,
ggtheme = theme_minimal(),
ylim = c(0, 35)
)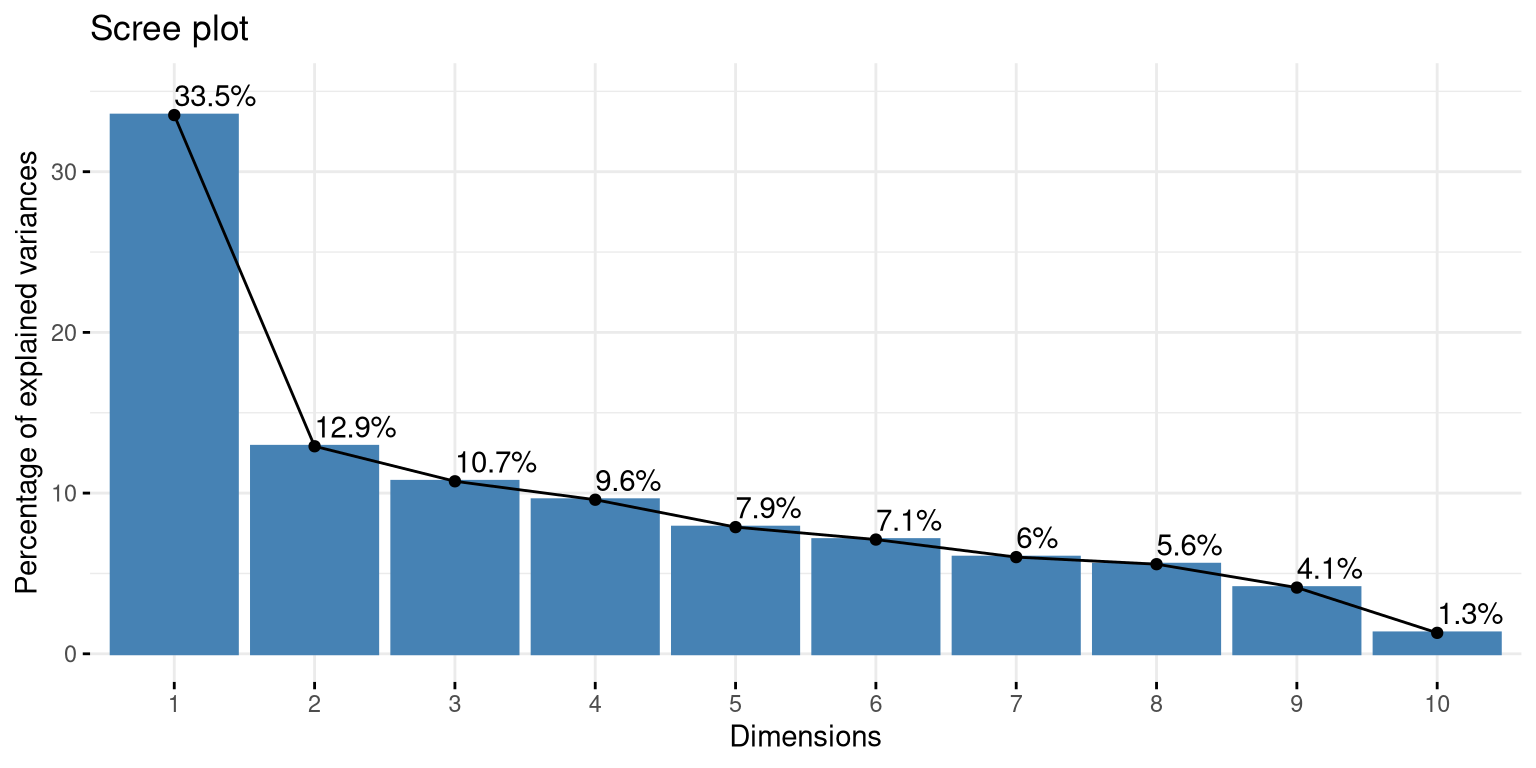
O scree plot indica que a primeira dimensão captura a maior parte da informação, e está bem acima do limiar de inércia média. Vamos focar nossa análise majoritariamente nela.
O biplot é a principal ferramenta de visualização. Ele mostra as categorias e os indivíduos no mesmo mapa, permitindo identificar perfis.
# Criar o biplot de indivíduos e variáveis
fviz_mca_biplot(mca_poison,
repel = TRUE, # Evita sobreposição de texto
ggtheme = theme_minimal(),
)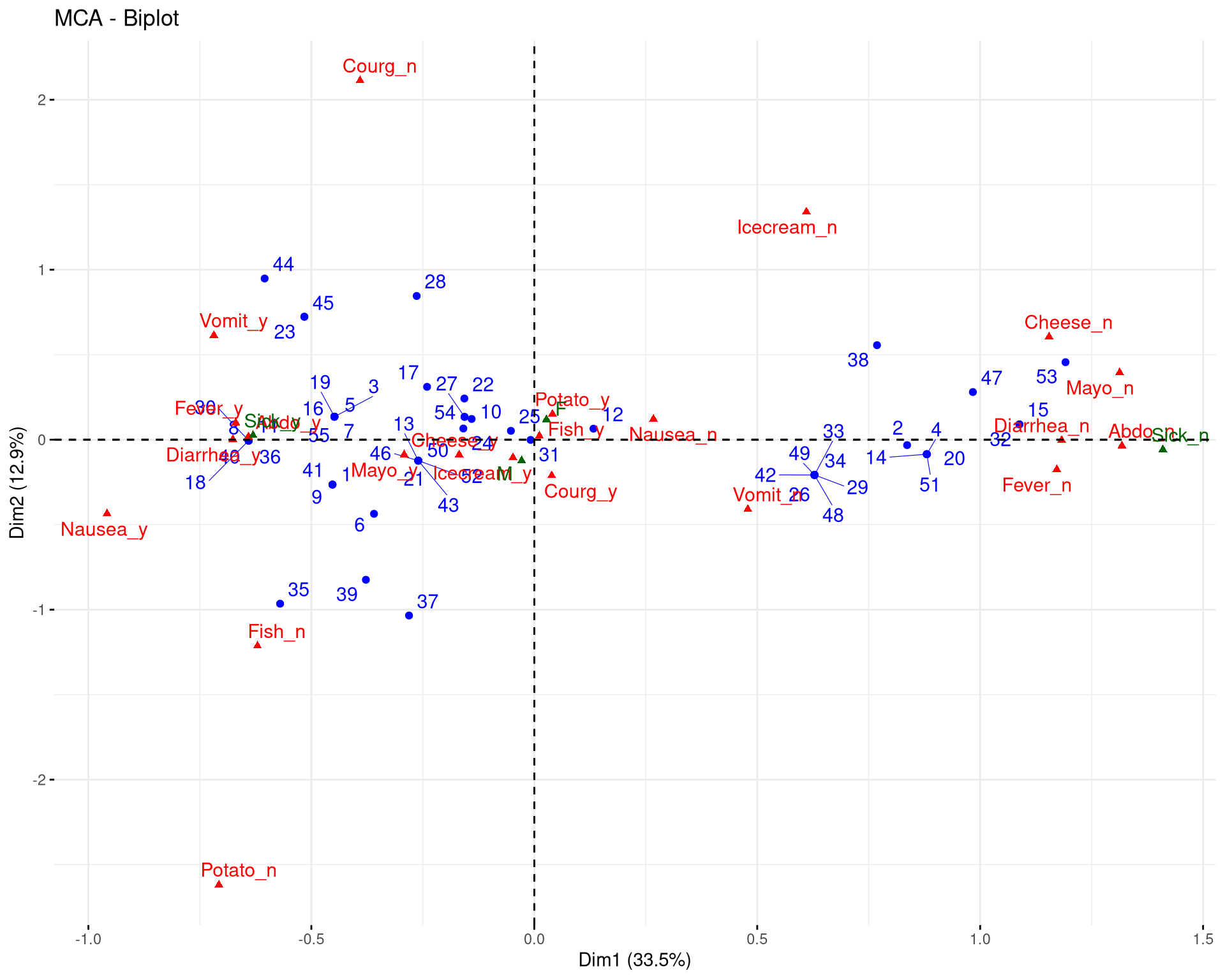
Interpretação do Biplot:
O mapa revela uma estrutura clara, muitas vezes chamada de “efeito de tamanho” ou estrutura em V, comum quando há um grupo muito distinto (neste caso, os doentes vs. saudáveis).
Diarrhoea_sim, Fever_sim, Vomiting_sim, Nausea_sim) e o estado Sick_sim.Sick_nao.Sick_y/Sick_n) não estão fortemente associadas a este eixo.Os gráficos de contribuição e qualidade (cos²) confirmam a importância das variáveis na definição dos eixos.
# Gráfico de contribuições para a Dimensão 1
p1 <- fviz_contrib(mca_poison, "var", axes = 1, top = 10)
# Gráfico de contribuições para a Dimensão 2
p2 <- fviz_contrib(mca_poison, "var", axes = 2, top = 10)
# Combinar os gráficos
p1 + p2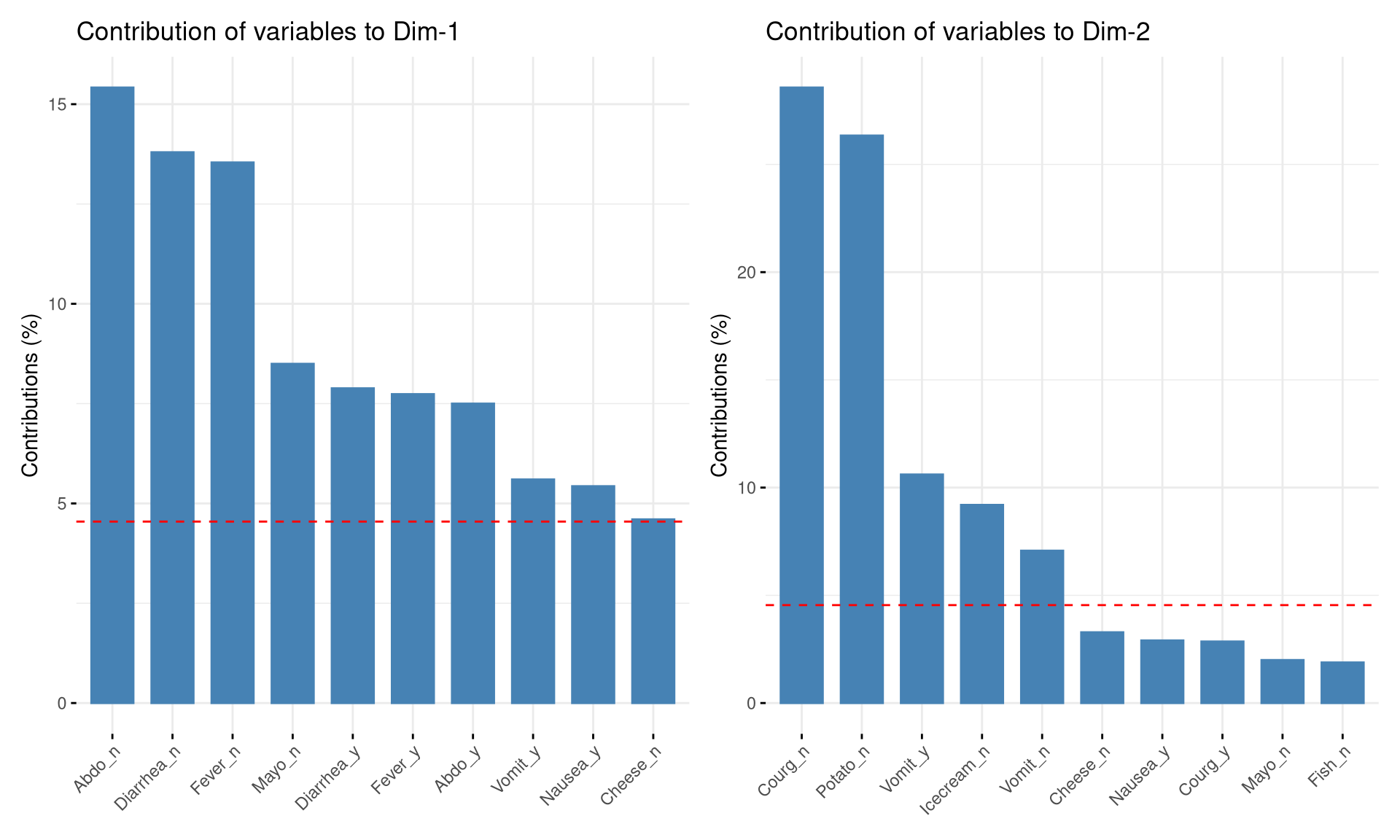
A análise sobre a tabela indicadora permite ver essa estrutura “Doente vs Saudável” como a principal fonte de variação nos dados.
Em análises de correspondência, é comum observar uma disposição dos pontos em forma de parábola ou ferradura (Horseshoe effect). Isso geralmente indica que a primeira dimensão é dominante e representa um gradiente latente forte (como “gravidade da doença” ou “tempo”), e a segunda dimensão é uma função quadrática da primeira. Se isso ocorrer, a interpretação deve focar principalmente na ordem ao longo da curva.
Uma extensão natural da ACM é o agrupamento (clustering) dos indivíduos. Como a ACM transforma as variáveis categóricas em coordenadas numéricas, podemos usar essas coordenadas para calcular distâncias entre indivíduos e agrupa-los.
O pacote FactoMineR oferece a função HCPC (Hierarchical Clustering on Principal Components) para isso.
# Realizar o agrupamento hierárquico sobre os resultados da ACM
res_hcpc <- HCPC(mca_poison, nb.clust = 3, graph = FALSE)
# Visualizar os clusters no mapa da ACM
fviz_cluster(res_hcpc,
repel = TRUE, # Evitar sobreposição
show.clust.cent = TRUE, # Mostrar o centroide de cada grupo
palette = "jco", # Paleta de cores
ggtheme = theme_minimal(),
main = "Agrupamento Hierárquico (HCPC) sobre ACM")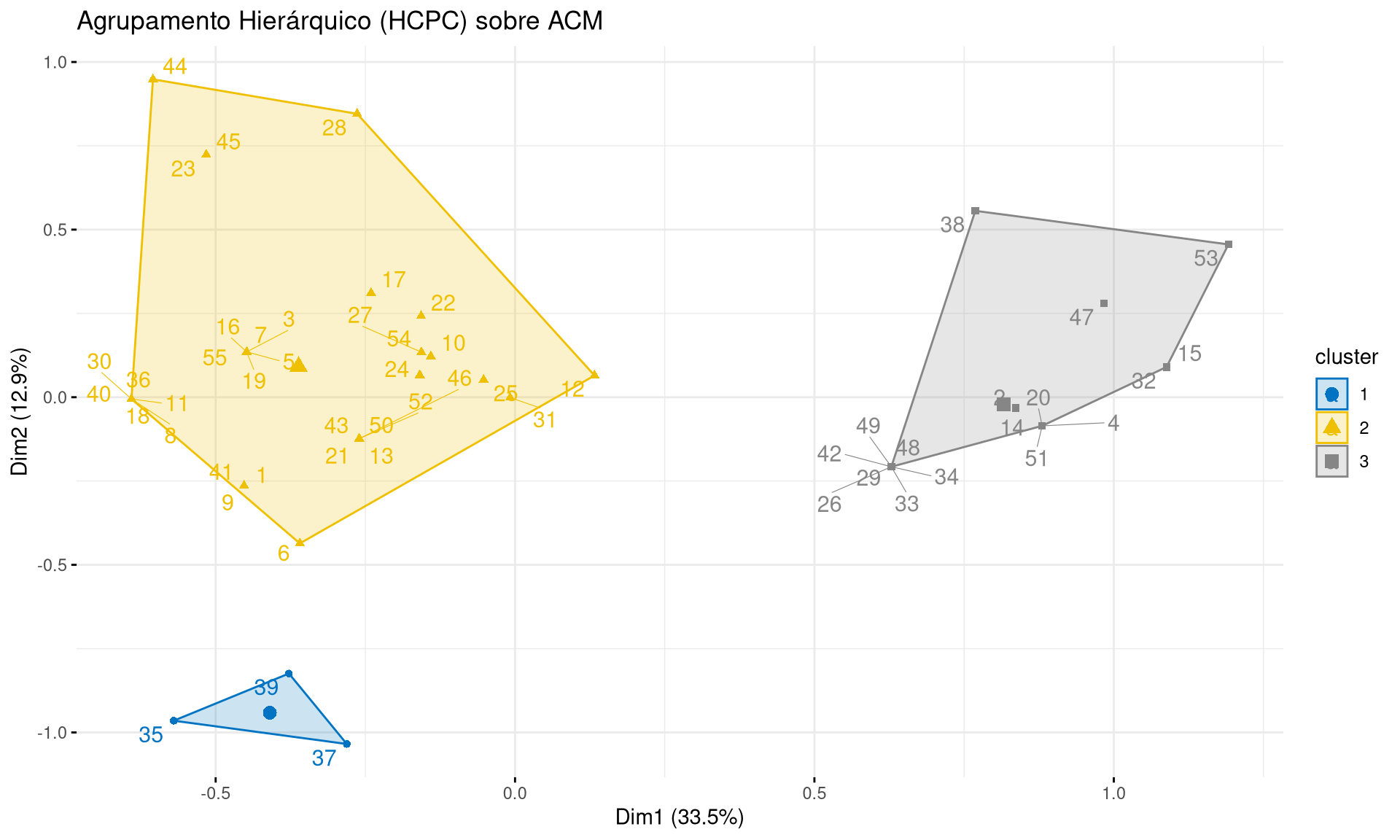
Fica como tarefa ao leitor identificar os clusters e interpretar sua significância.
teaQuando o número de indivíduos é grande (centenas ou milhares), o biplot de indivíduos se torna um borrão de pontos impossível de interpretar. Nesses casos, o foco da análise muda: em vez de analisar perfis de indivíduos, buscamos entender a estrutura de associações entre as variáveis.
Essa abordagem é conceitualmente ligada à Tabela de Burt, que é uma matriz de todas as tabelas de contingência de duas vias entre as variáveis. A ACM na tabela indicadora é matematicamente equivalente a uma Análise de Correspondência Simples (ACS) na tabela de Burt, e o mapa de variáveis resultante é o mesmo (com ajuste na escala).
Vamos usar o dataset tea, também do FactoMineR, que contém respostas de 300 indivíduos sobre seus hábitos de consumo de chá. Para facilitar a interpretação, vamos selecionar apenas 6 variáveis-chave que capturam os principais aspectos do comportamento de consumo:
data(tea)
# Selecionar apenas 5 variáveis-chave para facilitar interpretação:
# - Tea: tipo de chá preferido (black, green, Earl Grey)
# - How: como prepara (tea bag, unpackaged, etc)
# - how: forma de beber (alone, milk, lemon, etc)
# - where: onde compra (tea shop, chain store)
# - price: importância do preço (p_unknown, p_variable, p_branded, etc)
tea_ativa <- tea[, c("Tea", "How", "how", "where", "price")]
head(as_tibble(tea_ativa)) |>
knitr::kable()
# Ver resumo das categorias
summary(tea_ativa) Tea How how
black : 74 alone:195 tea bag :170
Earl Grey:193 lemon: 33 tea bag+unpackaged: 94
green : 33 milk : 63 unpackaged : 36
other: 9
where price
chain store :192 p_branded : 95
chain store+tea shop: 78 p_cheap : 7
tea shop : 30 p_private label: 21
p_unknown : 12
p_upscale : 53
p_variable :112 | Tea | How | how | where | price |
|---|---|---|---|---|
| black | alone | tea bag | chain store | p_unknown |
| black | milk | tea bag | chain store | p_variable |
| Earl Grey | alone | tea bag | chain store | p_variable |
| Earl Grey | alone | tea bag | chain store | p_variable |
| Earl Grey | alone | tea bag | chain store | p_variable |
| Earl Grey | alone | tea bag | chain store | p_private label |
O dataset tea original contém 18 variáveis ativas. Para este exemplo, selecionamos apenas 5 variáveis-chave por razões pedagógicas:
Tea, How, how, where, price) capturam os principais aspectos do comportamento de consumoEm uma análise real de mercado, você usaria todas as variáveis relevantes disponíveis.
Com 300 indivíduos, plotar pontos individuais seria inviável. Nosso objetivo é mapear as associações entre hábitos de consumo.
A seguir, visualizamos a tabela de Burt para o dataset tea. Ela nada mais é do que o cruzamento de todas as variáveis com todas as variáveis. Matematicamente, a Tabela de Burt é \(\mathbf{B} = \mathbf{Z}'\mathbf{Z}\), onde \(\mathbf{Z}\) é a matriz indicadora.
# Executar a ACM sobre a tabela indicadora
mca_tea <- MCA(tea_ativa, graph = FALSE)
# A função MCA internamente utiliza a matriz indicadora,
# mas podemos extrair ou calcular a tabela de Burt
# Criar matriz indicadora manualmente para demonstração
library(FactoMineR)
tea_matrix <- tab.disjonctif(tea_ativa)
# Calcular a tabela de Burt (Z'Z)
burt_table <- t(tea_matrix) %*% tea_matrix
# Visualizar a estrutura da tabela de Burt como heatmap
library(pheatmap)
pheatmap(burt_table,
display_numbers = FALSE,
cluster_rows = FALSE,
cluster_cols = FALSE,
color = colorRampPalette(c("white", "steelblue", "darkblue"))(50),
main = "Tabela de Burt - Dataset Tea",
fontsize = 7,
border_color = "grey90")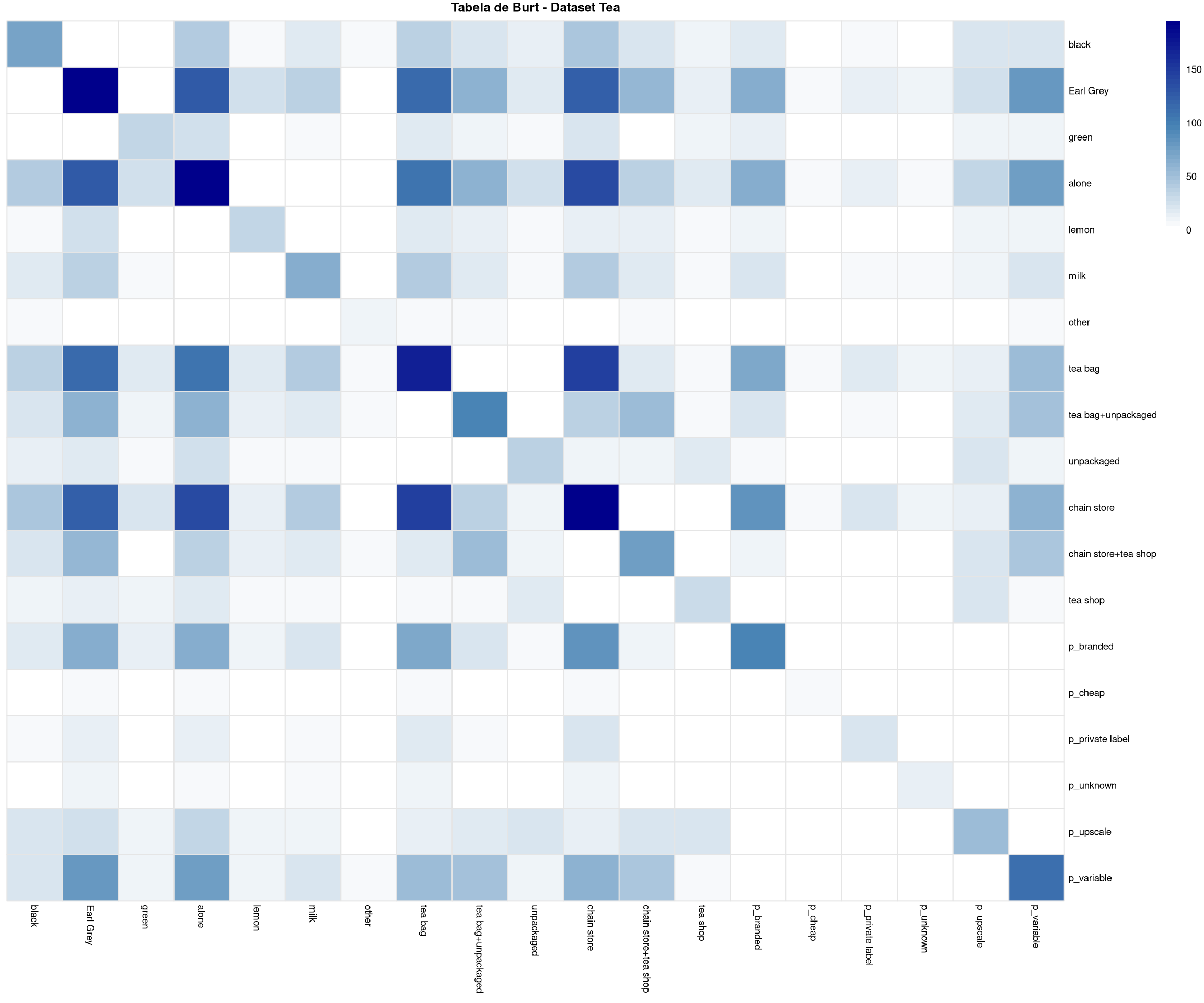
Interpretação da Tabela de Burt:
A tabela de Burt é uma matriz simétrica de dimensão \(J \times J\) (onde \(J\) é o total de categorias), construída como \(\mathbf{B} = \mathbf{Z}'\mathbf{Z}\). Sua estrutura é organizada em blocos:
O que o heatmap revela:
Observando o padrão de cores (células escuras = alta frequência de co-ocorrência):
Blocos bem definidos: Há regiões com concentrações claras de cor escura, sugerindo que certas combinações de hábitos são muito comuns. Por exemplo, categorias relacionadas a consumo prático (tea bag, supermercados) co-ocorrem frequentemente entre si.
Estrutura de blocos: A matriz não é uniforme - há “blocos escuros” indicando clusters de categorias que tendem a aparecer juntas, separados por regiões mais claras que indicam associações fracas ou negativas.
Simetria: Como esperado, a matriz é perfeitamente simétrica (a co-ocorrência de A com B é igual à de B com A), o que facilita a interpretação visual.
A ACM que executaremos a seguir decompõe essa tabela complexa de co-ocorrências em dimensões interpretáveis, permitindo visualizar os padrões em um espaço de baixa dimensão.
Agora executamos a ACM propriamente dita e analisamos a decomposição da inércia:
# O scree plot mostra a inércia de cada dimensão
fviz_screeplot(mca_tea,
addlabels = TRUE,
ggtheme = theme_minimal(),
ylim = c(0, 20))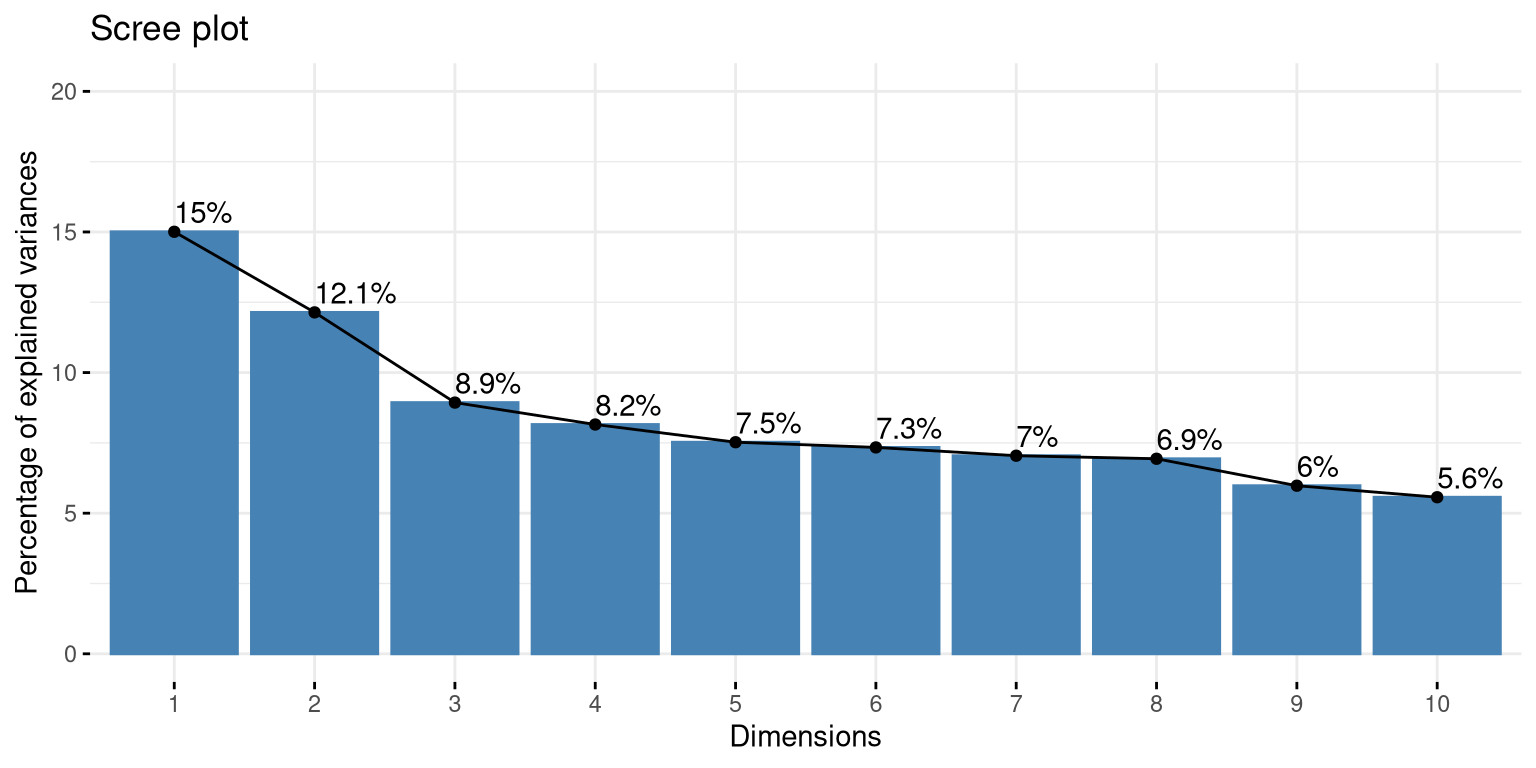
Interpretação do Scree Plot:
Como esperado em ACM, as porcentagens de inércia explicada parecem baixas à primeira vista. A primeira dimensão explica cerca de 15% da inércia total, e a segunda explica 12.1%. Isso NÃO significa que a análise é ruim! É uma característica intrínseca da ACM sobre a matriz indicadora.
Análise dos autovalores:
Conclusão: Apesar das porcentagens aparentemente baixas, as duas primeiras dimensões são altamente significativas pelo critério de Benzécri. Juntas, capturam os principais eixos de variação nos hábitos de consumo de chá.
Como discutido na Seção 11.7, a inércia total na ACM via matriz indicadora é fixa e depende do número de variáveis e categorias: \(\text{Inércia Total} = \frac{J - Q}{Q}\), onde \(J\) é o total de categorias e \(Q\) o número de variáveis.
Com 5 variáveis e 19 categorias totais, temos inércia total “estrutural” que dilui as porcentagens. O critério de Benzécri corrige essa distorção: uma dimensão é informativa se seu autovalor > \(1/Q\) (neste caso, > 0.20 ou 20%). Isso nos diz que devemos focar na magnitude relativa dos autovalores (acima vs. abaixo da média), não nas porcentagens absolutas.
Com 300 indivíduos, plotar todos os pontos seria inviável. Vamos focar exclusivamente no mapa de categorias, que nos permite entender a estrutura de associação entre as variáveis:
# Plotar apenas as variáveis (categorias), coloridas por qualidade de representação
fviz_mca_var(mca_tea,
repel = TRUE,
ggtheme = theme_minimal(),
col.var = "cos2", # Cor por qualidade de representação
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
title = "Mapa de Categorias - ACM Dataset Tea")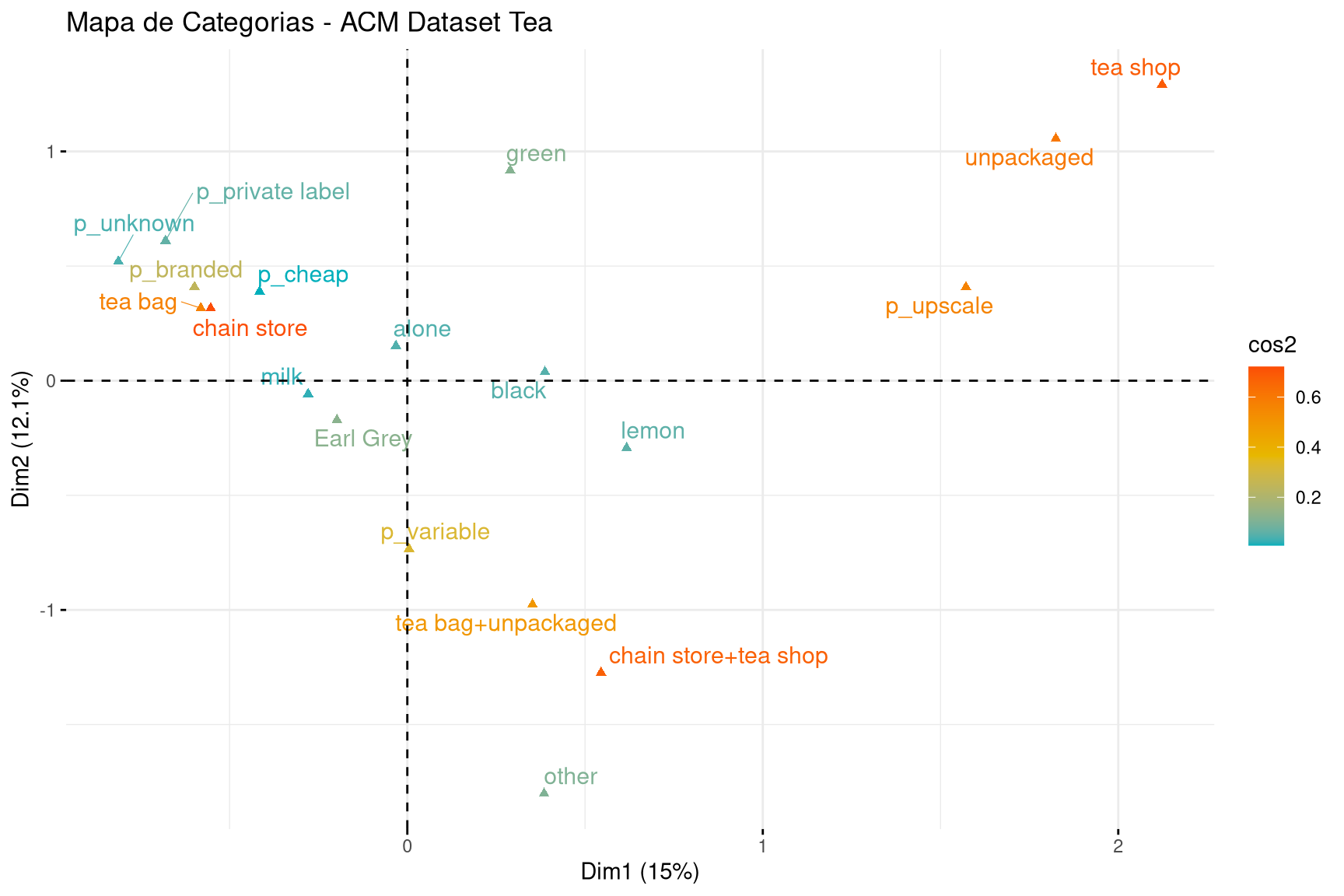
Interpretação do Mapa de Categorias:
O mapa revela a estrutura de associação entre os hábitos de consumo de chá dos 300 respondentes. As cores indicam a qualidade de representação (cos²): categorias em vermelho/laranja estão bem representadas no plano e podem ser interpretadas com confiança; categorias em azul têm parte de sua variabilidade em dimensões superiores.
Este é o principal eixo de diferenciação, separando consumidores por onde compram e que tipo de chá consomem:
LADO ESQUERDO (valores negativos):
chain store (supermercados/redes): Bem representado (cor laranja/vermelha)tea bag (sachês): Posicionado próximo a chain storeLADO DIREITO (valores positivos):
tea shop (lojas especializadas): Bem representado (cor vermelha)unpackaged (chá a granel): Fortemente associado a tea shopAssociação chave: chain store + tea bag vs. tea shop + unpackaged são perfis opostos, confirmando dois segmentos distintos de mercado.
A segunda dimensão diferencia os consumidores quanto ao tipo de chá preferido e consistência do comportamento:
PARTE SUPERIOR (valores positivos fortes):
green (+0.92): Chá verdetea shop (+1.29), unpackaged (+1.06): Reforçam a associação com chá verdePARTE INFERIOR (valores negativos fortes):
p_variable (-0.73): Preço variável/“depende”tea bag+unpackaged (-0.98): Combinação de categorias opostaschain store+tea shop (-1.27): Compra em ambos os canaisother (-1.80): Outro tipo de chá (não especificado)Significado da dimensão: Separa consumidores com perfil bem definido (extremos) de consumidores com comportamento misto/variável (centro e parte inferior)
A ACM revelou dois segmentos principais claramente separados pela Dimensão 1:
1. Perfil “Premium/Conhecedor” (lado direito do mapa):
tea shop)unpackaged)2. Perfil “Prático/Conveniência” (lado esquerdo do mapa):
chain store)tea bag)3. Categorias com baixa qualidade de representação (próximas à origem, cor azul):
how (forma de preparo) e Tea (tipo de chá específico)Insights acionáveis:
A ACM revelou insights claros sobre a estrutura do mercado de chá:
Principais descobertas:
tea shop), prefere chá a granel (unpackaged), disposto a pagar mais (p_upscale)chain store), usa sachês (tea bag), mais sensível a preçotea shop + unpackaged + p_upscale formam um cluster coerente (consumidor premium)chain store + tea bag formam o cluster de conveniênciatea shop+unpackaged vs. chain store+tea bag)