Código
# Gerar o gráfico de pares
sns.pairplot(iris, hue='especie', palette='viridis', height=2, aspect=1)
plt.show()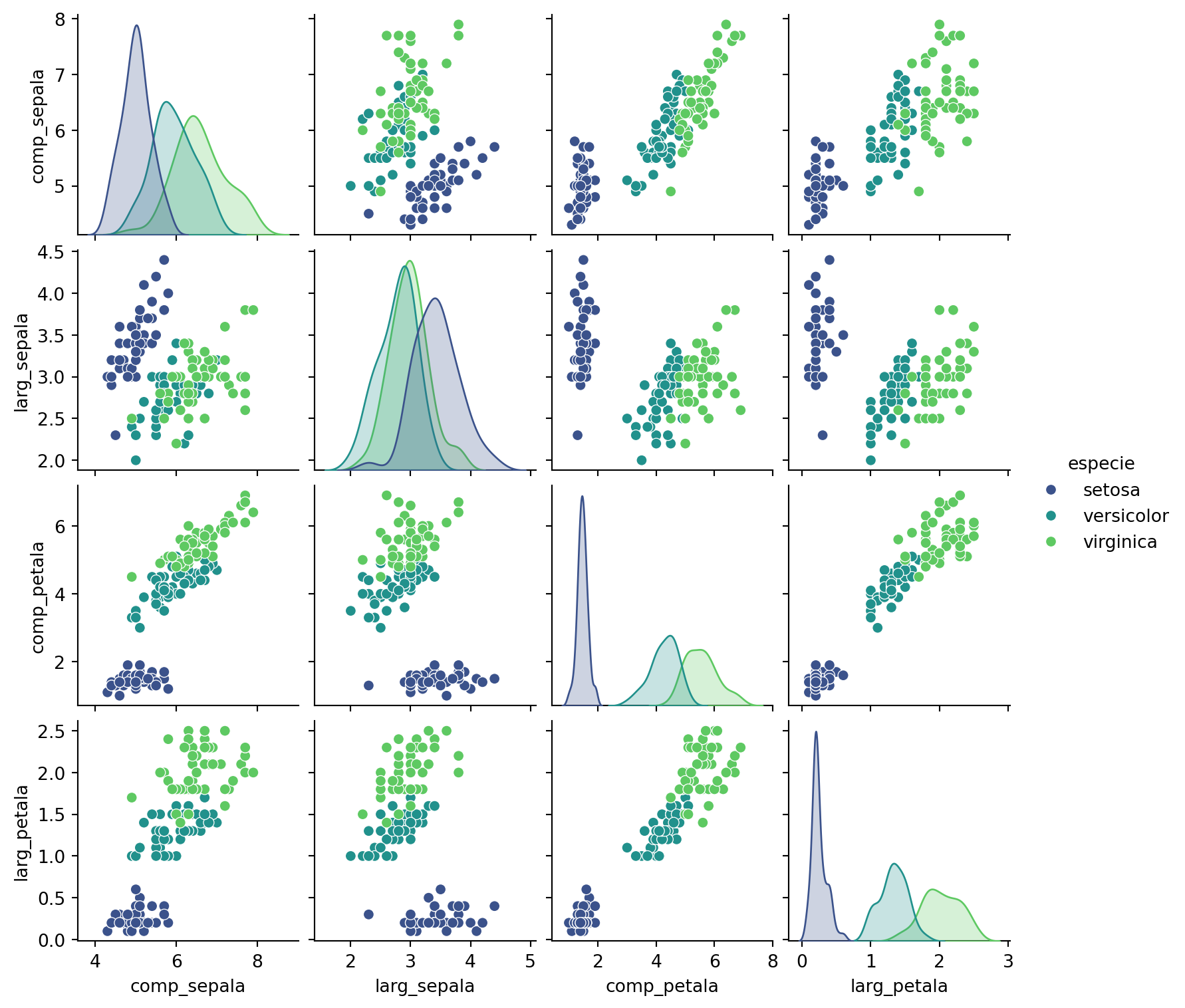
Neste exemplo, realizaremos uma Análise Discriminante com um dos conjuntos de dados mais clássicos da estatística: o dataset Iris, popularizado por R.A. Fisher em seu artigo de 1936, que introduziu a Análise Discriminante Linear.
O nosso foco será exploratório: queremos entender como as medidas das flores (variáveis) ajudam a distinguir as três espécies de íris (grupos). Em vez de focar na precisão da classificação de novas flores, vamos usar a LDA para encontrar as “visões” (projeções) que melhor separam os grupos e interpretar o que essas visões significam.
O conjunto de dados contém 150 observações de flores de íris, divididas igualmente em três espécies:
Para cada flor, quatro características foram medidas (em centímetros):
sepal_length)sepal_width)petal_length)petal_width)Queremos entender a distribuição de cada variável e como elas se relacionam, especialmente quando observamos os diferentes grupos. Vamos carregar os dados e visualizar um resumo descritivo e um gráfico de pares.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
# Carregar o dataset Iris
iris_data = load_iris()
iris = pd.DataFrame(data=iris_data.data, columns=iris_data.feature_names)
iris['especie'] = iris_data.target_names[iris_data.target]
# Renomear colunas para o português, para facilitar a interpretação
iris.columns = ['comp_sepala', 'larg_sepala', 'comp_petala', 'larg_petala', 'especie']
# Exibir as primeiras linhas
print(iris.head()) comp_sepala larg_sepala comp_petala larg_petala especie
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa# Gerar o gráfico de pares
sns.pairplot(iris, hue='especie', palette='viridis', height=2, aspect=1)
plt.show()Na figura, observamos algumas características interessantes:
Separação Clara da Setosa: A espécie Setosa é facilmente distinguível das outras duas. Suas pétalas são muito menores (comprimento e largura) e suas sépalas são mais largas e mais curtas. A separação é tão clara que um simples corte em comp_petala ou larg_petala poderia classificar quase todas as Setosas perfeitamente.
Sobreposição entre Versicolor e Virginica: As espécies Versicolor e Virginica são mais parecidas. Embora a Virginica tenda a ter pétalas e sépalas maiores que a Versicolor, há uma sobreposição considerável em todas as variáveis. É aqui que uma técnica multivariada como a Análise Discriminante se torna útil, pois pode encontrar uma combinação de variáveis que melhore a separação.
Correlações: O comprimento e a largura da pétala (comp_petala e larg_petala) são altamente correlacionados. O comprimento da sépala (comp_sepala) também tem uma correlação positiva com ambas.
A análise discriminante linear tem como suposição a homocedasticidade dos grupos. Ou seja, ela pressupõe que as matrizes de covariâncias de todos os grupos são iguais. A Figura 17.1 nos dá indícios de que tal suposição não é razoável. Em particular, a variância da largura e do comprimento da sépala do grupo Setosa parece bem inferior as demais. Ainda assim, vamos prosseguir com a LDA por razões didáticas.
A LDA busca encontrar as combinações lineares das variáveis originais — as funções discriminantes — que maximizam a razão entre a variância entre os grupos e a variância dentro dos grupos. Como temos \(k=3\) grupos e \(p=4\) variáveis, podemos encontrar no máximo \(\min(p, k-1) = \min(4, 2) = 2\) funções discriminantes.
Essas duas funções, LD1 e LD2, criarão um novo espaço 2D onde a separação dos grupos é otimizada.
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# Separar variáveis preditoras (X) e a variável resposta (y)
X = iris[['comp_sepala', 'larg_sepala', 'comp_petala', 'larg_petala']]
y = iris['especie']
# Criar e ajustar o modelo LDA
lda = LinearDiscriminantAnalysis(n_components=2)
X_lda = lda.fit_transform(X, y)
# Criar um DataFrame com os resultados
lda_df = pd.DataFrame(data=X_lda, columns=['LD1', 'LD2'])
lda_df['especie'] = y
# Plotar o resultado
plt.figure(figsize=(8, 6))
sns.scatterplot(x='LD1', y='LD2', hue='especie', data=lda_df, palette='viridis', s=70, alpha=0.8)
plt.title('Projeção da Análise Discriminante Linear')
plt.xlabel('Função Discriminante 1 (LD1)')
plt.ylabel('Função Discriminante 2 (LD2)')
plt.grid(True, linestyle='--', alpha=0.5)
plt.legend()
plt.show()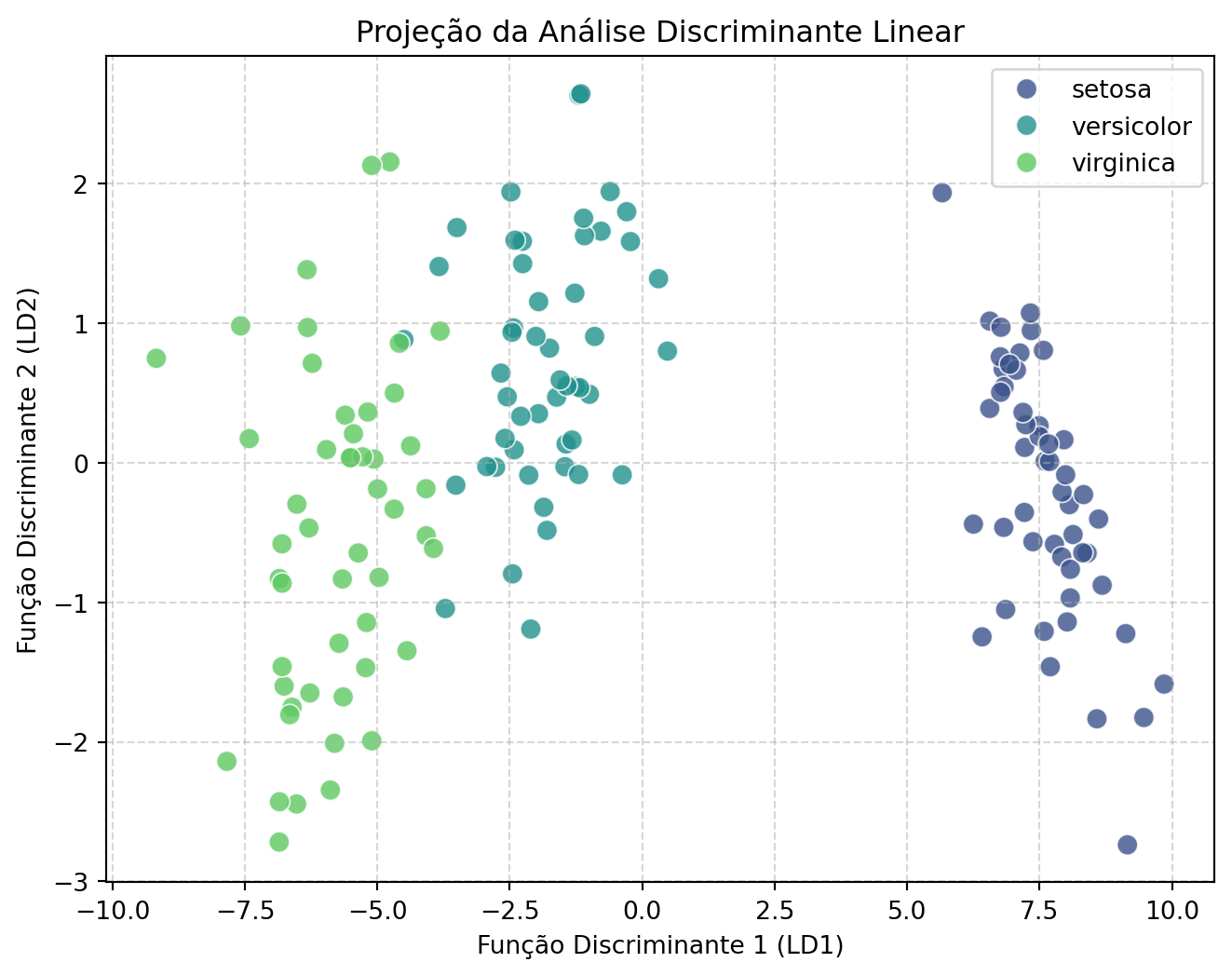
O gráfico da projeção LDA é bem informativo:
Juntas, as duas funções criam um mapa claro da estrutura dos grupos. Mas o que exatamente são LD1 e LD2? Para entender isso, precisamos olhar para os coeficientes (ou “loadings”) de cada função.
# Coeficientes das funções discriminantes
coeficientes = pd.DataFrame(lda.scalings_, index=X.columns, columns=['LD1', 'LD2'])
print("Coeficientes das Funções Discriminantes (Loadings):")
print(coeficientes)Coeficientes das Funções Discriminantes (Loadings):
LD1 LD2
comp_sepala 0.829378 -0.024102
larg_sepala 1.534473 -2.164521
comp_petala -2.201212 0.931921
larg_petala -2.810460 -2.839188Interpretando os Coeficientes:
LD1: Os coeficientes de maior magnitude são larg_petala (-2.81) e comp_petala (-2.20), ambos negativos, que se contrapõem aos coeficientes positivos de larg_sepala (1.53) e comp_sepala (0.83). Isso significa que a LD1 é uma medida de contraste entre o tamanho das pétalas e o tamanho das sépalas. Escores baixos em LD1 (valores negativos) são associados a flores com pétalas grandes, enquanto escores altos (valores positivos) estão associados a flores com pétalas pequenas e sépalas largas. Olhando o gráfico, vemos que a Setosa tem escores altos em LD1, o que é consistente com suas pétalas pequenas. Virginica e Versicolor têm escores negativos, correspondendo às suas pétalas maiores.
LD2: Esta função é dominada pelo contraste entre larg_sepala (-2.16) e larg_petala (-2.84), ambos com grandes coeficientes negativos, e comp_petala (0.93), com coeficiente positivo. Essencialmente, a LD2 separa flores com base em uma “forma” que opõe o comprimento da pétala à sua largura e à largura da sépala. Esta função é a principal responsável por separar a Versicolor (que tende a ter escores positivos em LD2) da Virginica (que tende a ter escores negativos), capturando as diferenças mais sutis entre essas duas espécies.
Enquanto a LDA assume que todos os grupos têm a mesma matriz de covariância (levando a fronteiras de decisão lineares), a Análise Discriminante Quadrática (QDA) relaxa essa suposição, permitindo fronteiras quadráticas mais flexíveis.
Vamos visualizar as fronteiras de decisão de ambos os modelos usando apenas duas variáveis: comp_petala e larg_petala. O objetivo disso é poder observar a diferença dos métodos visualmente de forma clara em duas dimensões. Ilustramos as regiões de discriminação na figura abaixo.
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from matplotlib.colors import ListedColormap
# Usar apenas as duas variáveis mais importantes para visualização
X_petal = iris[['comp_petala', 'larg_petala']]
y_petal = iris['especie']
# Mapear espécies para números para o plot
species_map = {species: i for i, species in enumerate(y_petal.unique())}
y_numeric = y_petal.map(species_map)
# Ajustar modelos LDA e QDA
lda_petal = LinearDiscriminantAnalysis()
lda_petal.fit(X_petal, y_petal)
qda_petal = QuadraticDiscriminantAnalysis()
qda_petal.fit(X_petal, y_petal)
# Criar uma malha de pontos para plotar as fronteiras
x_min, x_max = X_petal.iloc[:, 0].min() - 1, X_petal.iloc[:, 0].max() + 1
y_min, y_max = X_petal.iloc[:, 1].min() - 1, X_petal.iloc[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
# Criar um DataFrame com os pontos da malha para evitar o warning
grid_points = pd.DataFrame(np.c_[xx.ravel(), yy.ravel()], columns=X_petal.columns)
# Prever em cada ponto da malha
Z_lda = lda_petal.predict(grid_points)
Z_lda = np.array([species_map[label] for label in Z_lda]).reshape(xx.shape)
Z_qda = qda_petal.predict(grid_points)
Z_qda = np.array([species_map[label] for label in Z_qda]).reshape(xx.shape)
# Plotar
plt.figure(figsize=(8, 6))
# Plotar as áreas de decisão da QDA
cmap_light = ListedColormap(['#DAF7A6', '#FFC300', '#FF5733'])
plt.contourf(xx, yy, Z_qda, alpha=0.2, cmap=cmap_light)
# Plotar as fronteiras da LDA
plt.contour(xx, yy, Z_lda, colors='black', linestyles='--', linewidths=2)
# Plotar os pontos de dados
sns.scatterplot(x=X_petal.iloc[:, 0], y=X_petal.iloc[:, 1], hue=y_petal,
palette='viridis', alpha=0.9, edgecolor='k', s=80)
plt.title('Fronteiras de Decisão: LDA (tracejado) vs. QDA (fundo colorido)')
plt.xlabel('Comprimento da Pétala (cm)')
plt.ylabel('Largura da Pétala (cm)')
plt.legend(title='Espécie')
plt.show()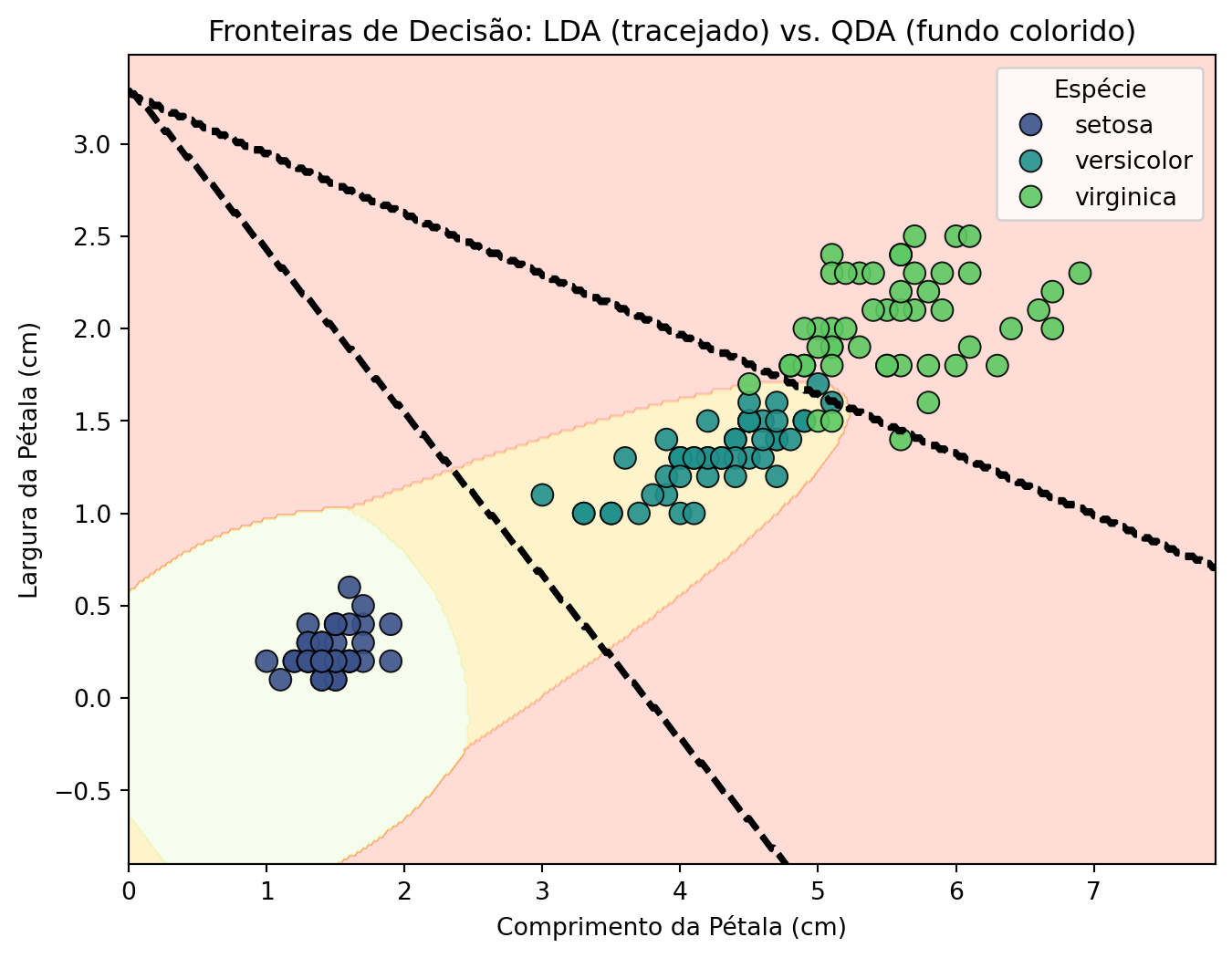
A visualização das fronteiras de decisão nos mostra:
Nesta análise exploratória, usamos a Análise Discriminante não apenas como um classificador, mas como uma ferramenta para redução de dimensionalidade e interpretação.